Atcoder泛做
一个长度为$N$的排列$P$,每次选一个区间,然后把区间$Mex$从这个排列中移除。问有多少排列$P$能通过以上操作最终得到一个长度为$M$的序列$A$
$M\leq N\leq500$
计数题,应该先找计数对象的特征。
首先拿$A$序列和$[1,N]$做一个差,就能得到每次移除的$Mex$。这些$Mex$一定从大到小移除的。因为如果反之,当我取更大$Mex$的时候会发现少了一个数而取不到。
选择一个原序列中的区间然后删除Mex的话,首先这个Mex一定不在区间中,并且$[0, Mex-1]$中的所有数都一定出现在这个区间里。那么假设$[0,Mex-1]$这些数在原序列中的区间是$[l,r]$,那么$Mex$一定在$[l,r]$的外面。
接下来是对于我来说比较容易忽略的点——每次移除操作不改变元素的相对位置,这样$A$序列就是原序列的一个子序列。
那么计数对象$P$的特征大概就是
- $A$是$P$的子序列
- 一个$Mex$必然在$[0,Mex-1]$形成的区间之外
考虑到$Mex$的位置由$[0,Mex-1]$确定,那么从小到大向序列中加数。
因为性质1,所有这里加数只能在$A$序列的空隙中加,一共有$M+1$个空位。
考虑性质2,当添加一个新数$i$的时候,我们还需要知道$[0,i-1]$的区间是多大,这样才能确定$i$的可选位置。
所以可以写出如下DP。
$dp[i][l][r]$表示前$i$个数,目前占据了$[l,r]$这些空位的序列方案数。当$i$是一个$Mex$的时候,考虑枚举$i$的位置,$i$可选的位置大概是$l$之前包括$l$,$r$之后包括$r$的所有空位。当$i$不是一个$Mex$的时候,最开始就卡在这里,实际上假设$i$的位置是$pos[i]$,那么枚举前$i-1$的空位$[l,r]$,跟当前$pos[i]$做一个并即可。
具体实现上DP的状态发生了一些变化。
$dp[i][l][r]$表示如果下一个$Mex$是$i$,当前$[l,r]$不可用的方案数。最终输出的结果是$dp[N][2][M]$,因为最左边和最右边的空位永远都可以用,且整个序列的$Mex$是$N$。由性质2,在$i$空位插入一个数,相当于屏蔽了$i-1$空位或$i+1$空位;如果是$A$序列中的$i$位置,相当于屏蔽了$i$空位或$i+1$空位。转移大差不差。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
int Main()
{
int N, M;
read(N, M);
std::vector<int> a(M + 1);
for (int i = 1; i <= M; ++i)
read(a[i]);
std::vector<std::vector<std::vector<modint>>> dp(N + 1, std::vector(M + 3, std::vector<modint>(M + 3)));
std::vector<int> pos(N, 0);
for (int i = 1; i <= M; ++i)
pos[a[i]] = i;
if (!pos[0])
{
for (int i = 1; i <= M + 1; ++i)
dp[1][i + 1][i - 1] = 1;
}
else
dp[1][pos[0] + 1][pos[0]] = 1;
for (int i = 1; i < N; ++i)
{
if (!pos[i])
{
for (int l = 2; l <= M + 2; ++l)
{
modint sum = 0;
for (int j = 1; j <= M + 1; ++j)
{
dp[i + 1][l][j - 1] += sum + dp[i][l][j - 1];
sum += dp[i][l][j - 1];
}
}
for (int r = 0; r <= M; ++r)
{
modint sum = 0;
for (int j = M + 1; j >= 1; --j)
{
dp[i + 1][j + 1][r] += sum + dp[i][j + 1][r];
sum += dp[i][j + 1][r];
}
}
}
else
{
for (int l = 2; l <= M + 2; ++l)
for (int r = 0; r <= M; ++r)
dp[i + 1][std::min(pos[i] + 1, l)][std::max(pos[i], r)] += dp[i][l][r];
}
// for (int l = 2; l <= M + 2; ++l)
// for (int r = 0; r <= M; ++r)
// printf("dp[%d][%d][%d] = %d\n", i + 1, l, r, dp[i + 1][l][r]);
}
printf("%d\n", dp[N][2][M]);
return 0;
}
|
总结一下:方向是对的,先根据题意找计数对象的特征。而且基本上分析差不多了,但是卡在枚举到$A$序列本身那个地方。实现的时候,这种维数比较多的转移写起来要非常非常小心且专心,每个决策对应的转移都要想得非常清楚,debug的时候要有耐心,手算即便很困难也不能弃疗。
有两个长度为$N$的序列$A$和$B$。给出一个长度$k$,选出$k$个下标组成集合$S$,求$\sum_{i \in S}A[i] - max_{i \in S}B[i]$。对于每个$k$,求这样的值
假设就一个$k$,按$B$排序,显然就是一个经典数据结构问题。选一个最好的$i$,使得$A[i-1]$之前的前$k-1$大+$A[i]-B[i]$最大。
但是现在很多个$k$,就得琢磨一下了。
一般来说这种都会有一个性质,比如单调性。对于某一个$k$,最好的是$i$。那么对于$k+1$,决策点不会小于$i$。
可以打表也可以证一下。
设$F_{i}(k)$表示前$i$个数前$k$大的和。对于$j < i$,有$F_{j-1}(k-1)+A[j]-B[j] < F_{i-1}(k-1)+A[i]-B[i]$
如果对于$k+1$,决策点是$j$,那么$F_{j}(k)+A[j]-B[j]>F_{i}(k)+A[i]-B[i]$。设$a_{i}[k]$表示前$i$个数第$k$大的数。那么$F_{j-1}(k-1)+a_{j}[k]+A[j]-B[j]>F_{i}(k)+a_{i}[k]+A[i]-B[i]$。由于$i>j$那么显然$a_{j}[k] \leq a_{i}[k]$,所以就矛盾了。那么可以知道决策一定是单调的。
利用类似DP单调性优化二分队列的思想,用一个栈维护决策以及对应区间,最终求解即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
|
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline", "fast-math", "unroll-loops", "no-stack-protector")
#include <bits/stdc++.h>
using ll = long long;
using uint = unsigned int;
using ull = unsigned long long;
#define lowbit(x) (x & (-x))
const int mod = 998244353;
const double PI = 3.14159265358;
std::mt19937 rng(std::random_device{}());
namespace FI
{
char B[1 << 16], *S = B, *T = B;
inline char getc()
{
return S == T && (T = (S = B) + fread(B, 1, 1 << 16, stdin), S == T) ? EOF : *S++;
}
inline void read()
{
}
template <typename Tp, typename... Types>
inline void read(Tp &o, Types &...Args)
{
o = 0;
bool s = 0;
char c = getc();
while (c > '9' || c < '0')
s |= c == '-', c = getc();
while (c >= '0' && c <= '9')
o = o * 10 + c - '0', c = getc();
if (s)
o = -o;
read(Args...);
}
} // namespace FI
using FI::read;
constexpr int MultiTestCases = 0;
constexpr int MAXN = 2e5;
struct Info
{
int v;
ll sum = 0;
int size = 0;
};
struct Merge
{
Info operator()(const Info &lhs, const Info &rhs) const
{
Info res;
res.sum = lhs.sum + rhs.sum;
res.size = lhs.size + rhs.size;
res.v = rhs.v;
return res;
}
};
struct PersistentSegmentTree
{
const int n;
const Merge merge;
struct node
{
std::array<int, 2> ch{};
Info info;
};
std::array<node, MAXN * 20 + 5> tree;
int cnt = 0;
PersistentSegmentTree(int _n) : n(_n), merge(Merge())
{
}
void pull(int p)
{
int ls = tree[p].ch[0], rs = tree[p].ch[1];
tree[p].info = merge(tree[ls].info, tree[rs].info);
}
int modify(int p, int l, int r, int x, const Info &v)
{
int q = ++cnt;
tree[q] = tree[p];
if (l == r)
return tree[q].info = merge(tree[p].info, v), q;
auto [ls, rs] = tree[p].ch;
int mid = (l + r) >> 1;
if (x <= mid)
tree[q].ch[0] = modify(ls, l, mid, x, v);
else
tree[q].ch[1] = modify(rs, mid + 1, r, x, v);
return pull(q), q;
}
int modify(int root, int p, const Info &v)
{
return modify(root, 1, n, p, v);
}
Info query(int p, int l, int r, int x, int y)
{
if (p == 0)
return Info{};
if (l == x && r == y)
return tree[p].info;
int mid = (l + r) >> 1;
auto [ls, rs] = tree[p].ch;
if (y <= mid)
return query(ls, l, mid, x, y);
else if (x > mid)
return query(rs, mid + 1, r, x, y);
else
return merge(query(ls, l, mid, x, mid), query(rs, mid + 1, r, mid + 1, y));
}
Info query(int root, int l, int r)
{
if (l > r)
return Info{};
return query(root, 1, n, l, r);
}
Info right_most(int p, int l, int r, int k)
{
if (k == 0)
return {};
if (l == r)
return {tree[p].info.v, 1ll * tree[p].info.v * k, k};
auto mid = (l + r) >> 1;
auto [ls, rs] = tree[p].ch;
if (tree[rs].info.size <= k)
return merge(right_most(ls, l, mid, k - tree[rs].info.size), tree[rs].info);
else
return right_most(rs, mid + 1, r, k);
}
Info right_most(int root, int k)
{
return right_most(root, 1, n, k);
}
};
std::pair<int, ll> A[MAXN + 5];
int roots[MAXN + 5];
struct Node
{
int i, l, r;
};
Node stack[MAXN + 5];
ll ans[MAXN + 5];
int Main()
{
int N;
read(N);
for (int i = 1; i <= N; ++i)
read(A[i].first, A[i].second);
std::sort(A + 1, A + N + 1,
[&](const std::pair<int, ll> &lhs, const std::pair<int, ll> &rhs)
{
return lhs.second < rhs.second;
});
std::set<int> set;
std::map<int, int> mp;
for (int i = 1; i <= N; ++i)
set.insert(A[i].first);
int cnt = 0;
for (int v : set)
mp[v] = ++cnt;
static PersistentSegmentTree segment_tree(cnt);
for (int i = 1; i <= N; ++i)
roots[i] = segment_tree.modify(roots[i - 1], mp[A[i].first], {A[i].first, A[i].first, 1});
auto cmp = [&](int j, int i, int k) -> bool
{
ll left = segment_tree.right_most(roots[j - 1], k - 1).sum + A[j].first - A[j].second;
ll right = segment_tree.right_most(roots[i - 1], k - 1).sum + A[i].first - A[i].second;
return left > right;
};
int top = 0;
for (int i = 1; i <= N; ++i)
{
while (top && !cmp(stack[top].i, i, stack[top].l))
top--;
if (top)
{
auto [j, l, r] = stack[top];
while (l <= r)
{
auto mid = (l + r) >> 1;
if (cmp(j, i, mid))
l = mid + 1;
else
r = mid - 1;
}
stack[top].r = r;
stack[++top] = {i, l, i};
}
else
stack[++top] = {i, 1, i};
}
while (top)
{
auto [i, l, r] = stack[top];
top--;
for (int k = l; k <= r; ++k)
{
Info res = segment_tree.right_most(roots[i - 1], k - 1);
ans[k] = res.sum + A[i].first - A[i].second;
}
}
for (int i = 1; i <= N; ++i)
printf("%lld\n", ans[i]);
return 0;
}
int main()
{
int TestCases = 1;
if constexpr (MultiTestCases == 1)
scanf("%d", &TestCases);
while (TestCases--)
Main();
return 0;
}
|
由于求解的内容没有前后依赖,可以使用更好写的决策单调性分治;并且由于决策点暴力转移时间复杂度不会更高的特性,可以避免使用可持久化线段树这样常数大的数据结构,实测下来真的差好多。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
|
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline", "fast-math", "unroll-loops", "no-stack-protector")
#include <bits/stdc++.h>
using ll = long long;
using uint = unsigned int;
using ull = unsigned long long;
#define lowbit(x) (x & (-x))
const int mod = 998244353;
const double PI = 3.14159265358;
std::mt19937 rng(std::random_device{}());
namespace FI
{
char B[1 << 16], *S = B, *T = B;
inline char getc()
{
return S == T && (T = (S = B) + fread(B, 1, 1 << 16, stdin), S == T) ? EOF : *S++;
}
inline void read()
{
}
template <typename Tp, typename... Types>
inline void read(Tp &o, Types &...Args)
{
o = 0;
bool s = 0;
char c = getc();
while (c > '9' || c < '0')
s |= c == '-', c = getc();
while (c >= '0' && c <= '9')
o = o * 10 + c - '0', c = getc();
if (s)
o = -o;
read(Args...);
}
} // namespace FI
using FI::read;
constexpr int MultiTestCases = 0;
template <class T, typename Merge = std::plus<T>>
struct FenwickTree
{
std::vector<T> fwt;
const Merge merge{};
int n;
#ifndef lowbit
inline int lowbit(int x) const
{
return (x & (-x));
}
#endif
FenwickTree(int _n) : n(_n), fwt(_n + 1)
{
}
void modify(int pos, T delta)
{
if (pos == 0)
return fwt[0] = merge(fwt[0], delta), void();
for (int i = pos; i <= n; i += lowbit(i))
fwt[i] = merge(fwt[i], delta);
}
T query(int pos) const
{
T res{};
if (pos < 0)
return res;
pos = std::min(pos, n);
for (int i = pos; i; i -= lowbit(i))
res = merge(res, fwt[i]);
res = merge(res, fwt[0]);
return res;
}
};
struct Info
{
ll sum = 0;
int size = 0;
};
Info operator+(const Info &lhs, const Info &rhs)
{
return {lhs.sum + rhs.sum, lhs.size + rhs.size};
}
int Main()
{
int n;
read(n);
std::vector<std::pair<ll, int>> a(n + 1);
for (int i = 1; i <= n; ++i)
read(a[i].second, a[i].first);
std::sort(a.begin() + 1, a.end());
std::vector<std::pair<int, int>> tab(n + 1);
for (int i = 1; i <= n; ++i)
tab[i] = {a[i].second, i};
std::sort(tab.begin() + 1, tab.end(), std::greater<std::pair<int, int>>{});
std::vector<int> p(n + 1);
for (int i = 1; i <= n; ++i)
p[tab[i].second] = i;
FenwickTree<Info> fwt(n);
static constexpr ll INF = 1e18;
int cur = 0;
auto f = [&](int i, int k)
{
if (i < k)
return -INF;
while (cur < i)
{
cur++;
fwt.modify(p[cur], {a[cur].second, 1});
}
while (cur > i)
{
fwt.modify(p[cur], {-a[cur].second, -1});
cur--;
}
int l = 1, r = n;
fwt.modify(p[i], {-a[i].second, -1});
while (l <= r)
{
auto mid = (l + r) >> 1;
auto [_, size] = fwt.query(mid);
if (size > k - 1)
r = mid - 1;
else
l = mid + 1;
}
ll res = fwt.query(r).sum + a[i].second - a[i].first;
fwt.modify(p[i], {a[i].second, 1});
return res;
};
std::vector<ll> ans(n + 1);
std::vector<int> cnt(n + 1);
std::function<void(int, int, int, int)> solve = [&](int l, int r, int dl, int dr)
{
int mid = (l + r) >> 1, best = dl;
ll mx = -INF;
for (int i = dl; i <= dr; ++i)
{
if (ll tmp = f(i, mid); tmp > mx)
mx = tmp, best = i;
}
// printf("%d %d\n", mid, best);
ans[mid] = mx;
for (int i = dl; i <= dr; ++i)
if (cnt[p[i]])
fwt.modify(p[i], {-a[i].second, -1}), cnt[p[i]]--;
if (l < mid)
solve(l, mid - 1, dl, best);
if (r > mid)
solve(mid + 1, r, best, dr);
};
solve(1, n, 1, n);
for (int i = 1; i <= n; ++i)
printf("%lld\n", ans[i]);
return 0;
}
int main()
{
int TestCases = 1;
if constexpr (MultiTestCases == 1)
scanf("%d", &TestCases);
while (TestCases--)
Main();
return 0;
}
|
总结一下:对于单个$k$,是典题;如果是多个$k$需要考虑特殊性质,一般来说都是一些单调性;在这道题里能隐隐约约感觉到这个单调性的存在,如果不想证明就直接打表;在有限的时间内(ABC只有100分钟)凭直觉猜结论这种能力还是很重要的。
决策单调性,二分队列是很常规的做法,基本上可以应对绝大部分的情况,然而一般来说这种算法的常数都比较大。在这里的体现是,比较两个决策点的优劣时旧决策点维护的数据结构要保留,所以只能使用可持久化数据结构,空间和时间常数都很大。

单调性分治的做法是对于$[l,r]$直接暴力求一个$mid$,得到子区间的决策上下界,再求$[l,mid-1]$和$[mid+1,r]$。如果是这种$dp[i] = dp[j]+w(j,i)$的式子,在$dp[l..mid-1]$求解之前无法确定$dp[mid]$的值,单调性分治就会失效,所以经常见于分层的动态规划。
$N$个技能,$M$个成就。技能升级需要花费,最高升五级。一个成就需要某些技能达到某些等级,获得某些回报。求最大的回报-花费是多少
一句话:最大权闭合子图…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#include <atcoder/maxflow>
int Main()
{
int n, m;
read(n, m);
std::vector<int> c(n + 1), a(m + 1);
for (int i = 1; i <= n; ++i)
read(c[i]);
for (int i = 1; i <= m; ++i)
read(a[i]);
int sum = std::accumulate(a.begin(), a.end(), 0);
std::vector l(m + 1, std::vector<int>(n + 1));
for (int i = 1; i <= m; ++i)
for (int j = 1; j <= n; ++j)
read(l[i][j]);
atcoder::mf_graph<int> graph(m + n * 5 + 2);
int s = 0, t = m + n * 5 + 1;
for (int i = 1; i <= n; ++i)
{
for (int k = 2; k <= 5; ++k)
graph.add_edge(m + (i - 1) * 5 + k, t, c[i]);//负权点向汇点
for (int k = 2; k <= 5; ++k)
graph.add_edge(m + (i - 1) * 5 + k, m + (i - 1) * 5 + k - 1, std::numeric_limits<int>::max());//高级向低级连边
}
for (int i = 1; i <= m; ++i)
{
graph.add_edge(s, i, a[i]);//正权点的边
for (int j = 1; j <= n; ++j)
graph.add_edge(i, m + (j - 1) * 5 + l[i][j], std::numeric_limits<int>::max());//正权点向依赖技能连边
}
auto cut = graph.flow(s, t);
std::cout << sum - cut << std::endl;
return 0;
}
|
总结一下:读题就建出模了,很典…
给出一个数组$A$和质数$P$,找出数对$(i,j)$满足:存在$k$使得$A_{i}^k \equiv A_{j} \bmod P$。$N\leq 2 \times 10^5, P\leq 10^{13}$
题目明示离散对数问题,考虑原根。一个奇素数必然存在原根,这个原根是模$P$运算的生成元,设这个原根是$g$,那么对于$[1,P-1]$中每个数,都是$g$的某次幂,且$g,g^2,…,g^{P-1}$是不同的数。
接下来考虑阶的定义。一个数$a=g^q$的阶$m$,指的是最小的$m$使得$a^m \equiv 1\bmod P$。注意到$g^{q * m} \equiv 1 \bmod P$,$m$是$a$的阶。那么$q * m$是$P-1$的倍数,且$m$是最小的,这样$q*m$就是$lcm(q,P-1)$。于是$m=\frac{gcd(P-1,q)}{d}$。
引入原根之后,可以把$A_i$写成$g^{q_i}$。于是就变成$g^{q_i * k}\equiv g^{q_j}\bmod P$。由于幂运算肯定有一个长度为$P-1$的环,那么相当于$q_i * k\equiv q_{j} \bmod (P-1)$。这个方程有解的前提是$q_j$是$gcd(q_i, P-1)$的倍数。等价于$gcd(q_j, P-1)|gcd(q_i, P-1)$。设$d[i] = gcd(q_i, P-1)$,统计$d[i]|d[j]$的个数。
由于$10^{13}$内的数最多有$11000$个左右的约数,所以暴力遍历是可行的,总次数大概是5e7的级别。
问题变成怎么求$d[i]$。朴素的想法肯定是找到原根$g$,然后挨个求幂次。第一想法是BSGS,而实际上BSGS算法的复杂度太高会TLE。其实这里我们只想要$d[i]$。所以用找到$a[i]$的阶就能找到$d[i]$。
所以问题变成了怎么求阶。$a^{P-1}\equiv 1 \bmod P$,然后$m$肯定是$P-1$的约数且是满足条件最小的那个。可以考虑把$P-1$质因数分解,一个一个质因数往下除,直到幂次不为1。一共有$O(log_{2}(P-1))$个质因数,每次求快速幂都有$O(log_{2}P)$的复杂度,因此总复杂度是$O(Nlog_{2}^2P)$。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
int Main()
{
int n;
ll p;
read(n, p);
std::vector<ll> a(n + 1);
for (int i = 1; i <= n; ++i)
read(a[i]);
if (p == 2)
{
int z0 = 0, z1 = 0;
for (int i = 1; i <= n; ++i)
z0 += (a[i] % 2) == 0, z1 += (a[i] % 2);
std::cout << 1ll * z0 * z0 + 1ll * z1 * z1 << std::endl;
return 0;
}
std::vector<ll> order(n + 1);
std::vector<int> prime;
static constexpr int MX = 3.2e6;
static std::array<int, MX> mnp{};
for (int i = 2; 1ll * i * i <= p; ++i)
{
if (!mnp[i])
mnp[i] = i, prime.push_back(i);
for (int pr : prime)
{
if (1ll * pr * i * i * pr > p)
break;
mnp[i * pr] = pr;
if (i % pr == 0)
break;
}
}
auto pow = [&](ll x, ll q) -> ll
{
if (q == 0)
return 1;
__uint128_t ans = 1, base = x;
while (q)
{
if (q & 1)
ans = ans * base % p;
q >>= 1;
base = base * base % p;
}
return ans % p;
};
std::vector<std::pair<ll, int>> pfactors;
ll q = p - 1;
for (int pr : prime)
{
int size = 0;
while (q % pr == 0)
{
size++;
q /= pr;
}
if (size)
pfactors.emplace_back(pr, size);
}
if (q != 1)
pfactors.emplace_back(q, 1);
for (int i = 1; i <= n; ++i)
{
order[i] = p - 1;
for (auto [pr, size] : pfactors)
{
while (size--)
{
if (pow(a[i], order[i] / pr) == 1)
order[i] /= pr;
else
break;
}
}
}
std::vector<ll> d(n + 1);
for (int i = 1; i <= n; ++i)
d[i] = (p - 1) / order[i];
std::map<ll, int> mp;
for (int i = 1; i <= n; ++i)
mp[d[i]]++;
std::vector<std::pair<ll, int>> buc;
for (auto [gcd, size] : mp)
buc.emplace_back(gcd, size);
ll ans = 0;
for (int i = 0; i < buc.size(); ++i)
{
ans += 1ll * buc[i].second * buc[i].second;
for (int j = i + 1; j < buc.size(); ++j)
if (buc[j].first % buc[i].first == 0)
ans += 1ll * buc[i].second * buc[j].second;
}
std::cout << ans << std::endl;
return 0;
}
|
总结一下:涉及很多离散对数、原根和阶的基础知识和引理。从引入原根开始,思路是很自然的,前提是懂知识点,是一道很好的例题。ABC果然很Educational。感觉还应该记一下各数量级的超级合数的东西,快速推定约数个数的最大值,方便计算复杂度。
OEIS链接。
然后Codeforces的讨论中提到可以使用$O(N^{\frac{1}{3}})$来估算。
一棵$N$个节点的树,有一个棋子和传送门,任意节点开始遍历整棵树。有三种操作:
- 沿一条边移动棋子,花费为1
- 将棋子移动到传送门处,没有花费
- 将传送门移动到棋子处,没有花费
问最少的遍历花费是多少
$N \leq 2 \times 10^5$
一个重要的分析是,先移动棋子,然后移动传送门,等价于棋子和传送门同时沿一条边移动,花费为1。然后假设棋子最终停在某一个节点上,将棋子移动回传送门,同样不增加花费。这样初始状态和终止状态,棋子和传送门都在相同的位置。
这样我们要考虑的就是从哪一个节点开始走、到哪一个节点停止。假设没有传送门,显然问题的答案是$2(N-1)-d$其中$d$是直径。如果考虑传送门,那么需要考虑传送门是否跟着棋子一起走,如果跟着走,是否还会回到原位置。
可以考虑如下树形DP。
$dp[v][0]$表示当前子树没有传送门从$v$开始的遍历花费,显然是经典问题,维护最大深度和子树大小即可。
$dp[v][1]$表示当前子树棋子和传送门都在$v$,且终点不在该子树中的遍历花费。对于每一个子树,考虑传送门是否跟着走,如果跟着走,走一条边的花费是2
$dp[v][2]$表示当前子树棋子和传送门都在$v$,且终点在该子树中的遍历花费。考虑在当前根节点处终止,花费就是$dp[v][1]$,否则找一个子树终止,其它子树按传送门跟着走和不跟着走的决策讨论。
这样解决了从1节点开始的遍历问题,考虑从任意节点开始的遍历问题,显然换根DP即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
int Main()
{
int n;
read(n);
std::vector adj(n + 1, std::vector<int>{});
for (int i = 1, u, v; i <= n - 1; ++i)
{
read(u, v);
adj[u].push_back(v), adj[v].push_back(u);
}
std::vector<int> size(n + 1), dep(n + 1);
std::vector<std::array<int, 2>> mxdep(n + 1);
std::vector<std::array<int, 3>> dp(n + 1);
std::function<void(int, int)> DP = [&](int u, int fa) -> void
{
size[u]++;
dep[u] = dep[fa] + 1;
mxdep[u][0] = dep[u];
if (fa != 0)
adj[u].erase(std::find(adj[u].begin(), adj[u].end(), fa));
for (int v : adj[u])
DP(v, u);
for (int v : adj[u])
{
size[u] += size[v];
if (mxdep[v][0] > mxdep[u][0])
{
mxdep[u][1] = mxdep[u][0];
mxdep[u][0] = mxdep[v][0];
}
else
mxdep[u][1] = std::max(mxdep[u][1], mxdep[v][0]);
}
dp[u][0] = 2 * (size[u] - 1) - (mxdep[u][0] - dep[u]);
int tmp = 0;
for (int v : adj[u])
tmp += std::min(dp[v][0] + 1, dp[v][1] + 2);
dp[u][2] = dp[u][1] = tmp;
for (int v : adj[u])
dp[u][2] = std::min(dp[u][2], tmp - std::min(dp[v][0] + 1, dp[v][1] + 2) + dp[v][2] + 1);
// printf("dp[%d] = {%d, %d, %d}\n", u, dp[u][0], dp[u][1], dp[u][2]);
};
DP(1, 0);
int ans = std::numeric_limits<int>::max();
std::function<void(int, int, std::array<int, 3>)> reroot = [&](int u, int dist, std::array<int, 3> from)
{
int tmp = 0;
ans = std::min({ans, dp[u][1] + std::min(from[0] + 1, from[1] + 2), dp[u][1] + from[2] + 1, dp[u][2] + std::min(from[0] + 1, from[1] + 2)});
std::vector<std::array<int, 2>> pre(adj[u].size() + 1), suf(adj[u].size() + 2);
for (int i = 1; i <= adj[u].size(); ++i)
{
int v = adj[u][i - 1];
pre[i][0] = pre[i - 1][0] + std::min(dp[v][0] + 1, dp[v][1] + 2);
pre[i][1] = std::min(pre[i - 1][0] + dp[v][2] + 1, pre[i - 1][1] + std::min(dp[v][0] + 1, dp[v][1] + 2));
}
for (int i = adj[u].size(); i >= 1; --i)
{
int v = adj[u][i - 1];
suf[i][0] = suf[i + 1][0] + std::min(dp[v][0] + 1, dp[v][1] + 2);
suf[i][1] = std::min(suf[i + 1][0] + dp[v][2] + 1, suf[i + 1][1] + std::min(dp[v][0] + 1, dp[v][1] + 2));
}
for (int i = 1; i <= adj[u].size(); ++i)
{
int v = adj[u][i - 1];
std::array<int, 3> f{};
int mxd = (mxdep[v][0] == mxdep[u][0]) ? mxdep[u][1] : mxdep[u][0];
mxd -= dep[u];
mxd = std::max(dist, mxd);
f[0] = 2 * (n - size[v] - 1) - mxd;
f[1] = std::min(from[0] + 1, from[1] + 2) + suf[i + 1][0] + pre[i - 1][0];
f[2] = std::min({f[1], from[2] + 1 + suf[i + 1][0] + pre[i - 1][0], std::min(from[0] + 1, from[1] + 2) + suf[i + 1][1] + pre[i - 1][0], std::min(from[0] + 1, from[1] + 2) + suf[i + 1][0] + pre[i - 1][1]});
reroot(v, mxd + 1, f);
}
};
reroot(1, 0, {-1, -2, -1});
std::cout << ans << std::endl;
return 0;
}
|
总结一下:最重要的一步是合并操作3和操作1,这样传送门的决策就变少了,对于原题的分析就简化了。回传送门的操作没有额外花费,化简了终止状态。这样整个问题剩下的思路就很自然,从子树DP到换根DP都是经典问题。所以问题的解决要挖掘性质,方便分析或者程序处理。
有$N$种球,每种球有$A[i]$个。$M$个盒子,每种盒子有$B[i]$的容量。第$i$种球在第$j$个盒子里最多放$i \times j$个。问最多能放多少个球。
$N \leq 500, M \leq 5 \times 10^5$
好好好,好题。
首先是个很显然的最大流的模型。但是二分图每两个点之间都有边,边数超多。
然后是重点转化过程——从最大流转化到最小割。然后有三种边要割,$S$到$A[i]$的边,$A[i]$到$B[j]$的边,$B[j]$到$T$的边。由于是最小割,所以一旦割了$S->A[i]$的边,就不用考虑$A[i]$往后的边。
假设枚举割掉的源点相连的边集$U$,剩余集合是$V$,那么$B[j]$有两种决策,要么对于$V$到$B[j]$都割掉,要么割掉$B[j]$。发现前者对应的是$V$中节点标号之和与$j$的乘积,显然对于不同的$V$只要节点标号之和相同,对应的$j$的决策肯定相同。不妨直接枚举节点标号之和$sum$。
这样需要计算的变成了两个部分——对于$A[i]$,节点标号之和为$N(N+1)/2-sum$时的最小$A[i]$之和——显然是个背包;对于$B[j]$,选择$min(B[j],sum * j)$,按顺序枚举$sum$之后就是个单调性问题。两者独立,然后加和求最小。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
int Main()
{
int n, m;
read(n, m);
std::vector<ll> a(n + 1), b(m + 1);
for (int i = 1; i <= n; ++i)
read(a[i]);
for (int i = 1; i <= m; ++i)
read(b[i]);
int w = n * (n + 1) / 2;
std::vector dp(2, std::vector<ll>(w + 1, std::numeric_limits<ll>::max()));
dp[0][0] = 0;
for (int i = 1; i <= n; ++i)
{
for (int j = 0; j <= w; ++j)
{
if (dp[0][j] != std::numeric_limits<ll>::max())
dp[1][j] = std::min(dp[0][j], dp[1][j]);
if (j >= i && dp[0][j - i] != std::numeric_limits<ll>::max())
dp[1][j] = std::min(dp[0][j - i] + a[i], dp[1][j]);
}
std::swap(dp[1], dp[0]);
}
std::vector<std::pair<ll, int>> c(m + 1);
for (int i = 1; i <= m; ++i)
c[i] = {b[i], i};
std::sort(c.begin() + 1, c.end(),
[&](auto l, auto r)
{
return l.first * r.second > r.first * l.second;
});
std::vector<std::array<ll, 2>> sum(m + 1);
for (int i = 1; i <= m; ++i)
sum[i][0] = sum[i - 1][0] + c[i].first, sum[i][1] = sum[i - 1][1] + c[i].second;
ll ans = std::numeric_limits<decltype(ans)>::max();
for (int s = w, p = 1; s >= 0; --s)
{
if (dp[0][w - s] == std::numeric_limits<ll>::max())
continue;
while (p <= m && c[p].first > 1ll * c[p].second * s)
p++;
ans = std::min(ans, dp[0][w - s] + sum[p - 1][1] * s + sum[m][0] - sum[p - 1][0]);
}
std::cout << ans << std::endl;
return 0;
}
|
总结一下:这个最小割的转化太惊人了。我是没想到的。但是是有端倪的,从本质上说这是一个完全二分图而且点权是一个简单的式子,应该会存在简单的做法。其实转化到最小割之后整个思路就很自然了,从复杂的集合枚举到找到集合最有用的特征,然后归约到已知问题,这是一个常见的CP题目分析法。
在一个$N$个点$M$条边的单向强连通图中,每条边要么是(要么是)。判定是否存在一个经过了所有边至少一次,且遍历顺序是一个合法的括号序列的环。$N \leq 4000, M\leq8000$
首先这个环不一定非得是合法的括号序列,只要正反括号数量相等即可。设正反括号权值分别为1和-1,只要找到最小的负数前缀和,从这个点开始走,就是一个合法的括号序列了。
所有要找的是一个权值为0的环。
因为图强联通,所有必然存在一个环经过了所有边。假设这个环的权值是正数,相当于我们要拿一些负数去找补成0。只要存在一个负数环,就可以找补成0。因为组成正数权值和负数权值的LCM,加起来就是0了。对于这个环权值是负数也是一样的。
所以问题变成,是否存在正数环以及负数环;如果都存在或都不存在,答案是Yes;否则答案是No,因为永远找补不回0。
搜环是Spfa的一个子应用,套用即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
int Main()
{
int n, m;
scanf("%d%d", &n, &m);
std::vector adj(n + 1, std::vector<std::array<int, 2>>{});
for (int i = 1; i <= m; ++i)
{
int u, v;
char c[2];
scanf("%d%d%s", &u, &v, c);
int w = (c[0] == '(') ? 1 : -1;
adj[u].push_back({v, w});
}
auto BellmanFord = [&]() -> bool
{
std::vector<int> dist(n + 1), cnt(n + 1);
std::vector<bool> vis(n + 1);
std::queue<int> q;
for (int i = 1; i <= n; ++i)
q.push(i), vis[i] = true;
while (!q.empty())
{
int u = q.front();
vis[u] = false;
cnt[u]++;
if (cnt[u] > n)
return true;
q.pop();
for (auto [v, w] : adj[u])
{
if (dist[v] < dist[u] + w)
{
dist[v] = dist[u] + w;
if (!vis[v])
q.push(v), vis[v] = true;
}
}
}
return false;
};
bool neg = BellmanFord();
for (int i = 1; i <= n; ++i)
for (auto &[_, w] : adj[i])
w = -w;
bool pos = BellmanFord();
bool res = neg ^ pos ^ 1;
if (res)
printf("Yes\n");
else
printf("No\n");
return 0;
}
|
总结一下:有点抽象的推理题。解法有点像局部搜索,假设有一个解,然后用这个解去靠近最优解,然后分析性质才能得到解的充要条件。CP题需要很多假设以及简单的暴力,要有抽象思考问题的能力。能不着眼于具体的case,眼光着眼于整个问题才能得到优秀的解法。
给出一个长度为$N$的排列$P$,每次操作任选两个不相等的下标$i$和$j$,交换$P[i]$和$P[j]$。求所有可能的$M$次操作后,$\sum_{i=1}^{N-1}|P[i]-P[i+1]|$值。
只能说是学到新东西了。
设$l=min(P[i],P[i+1]),r=max(P[i],P[i+1])$,一对间隔的计算相当于数$l<k\leq r$的$k$的数量。假设枚举$k$,找到每个$k$能提供贡献的位置和数量就可以计算总贡献。据说这个叫切糕模型,来源于一个网络流题目
[HNOI2013] 切糕,会去补一下。考虑把原序列转化为01串$s$,$s[i]=P[i]\geq k$,那么显然在$s$串中01和10的出现会提供贡献。
接下来是一个神奇的东西。
因为每次交换是等概率选取一对数而且每次操作独立,所以每个状态到新状态的选法是一样的。很新奇的思路。
假设原串中一个00,意味着$P[i]<k,P[i+1]<k$,变成同样是00的位置,方案有
- 选一个$i,i+1$之外的小于$k$的数,一共有$k-3$个,跟$i$和$i+1$交换,一共有$2(k-3)$种选法;
- 交换$i,i+1$,显然只有一种
- 交换除了$i,i+1$之外的两个数,一共是$C_{n-2}^{2}$种选法
所以最终能写出一个矩阵$Mat$。
$Mat=\begin{bmatrix}
C_{n-2}^{2}+2(k-3)+1&n-k+1&n-k+1&0\
k-2&C_{n-2}^{2}+n-2&1&n-k\
k-2&1&C_{n-2}^{2}+n-2&n-k\
0&k-1&k-1&C_{n-2}^{2}+2(n-k-1)+1
\end{bmatrix}$。那么经过$M$次操作,状态的变换就是$Mat^m$。
接下来只需要枚举$k$,统计原序列中00,01,10,11的出现数做成一个向量$v$。经过矩阵的变换,求解变换之后的方案数,对总答案贡献即可。看起来是$O(N^2 * 4^3 * log_{2}M)$,实际上每次枚举到一个新的$k$,只需要关注$p[i]=k-1$前后的两个位置,去更新$v$即可。复杂度是$O(N * 4^3 * log_{2}M)$。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
#include <atcoder/modint>
using modint = atcoder::modint998244353;
struct Matrix
{
std::array<std::array<modint, 4>, 4> a{};
Matrix operator*(const Matrix &rhs) const
{
Matrix res{};
for (int i = 0; i < 4; ++i)
for (int j = 0; j < 4; ++j)
for (int k = 0; k < 4; ++k)
res.a[i][j] += a[i][k] * rhs.a[k][j];
return res;
}
};
Matrix quick_pw(Matrix a, ll b)
{
static Matrix I{std::array<std::array<modint, 4>, 4>{std::array<modint, 4>{1, 0, 0, 0}, {0, 1, 0, 0}, {0, 0, 1, 0}, {0, 0, 0, 1}}};
if (b == 0)
return I;
Matrix ans = I, base = a;
while (b)
{
if (b & 1)
ans = ans * base;
b >>= 1;
base = base * base;
}
return ans;
}
int Main()
{
int n, m;
read(n, m);
std::vector<int> p(n + 1);
for (int i = 1; i <= n; ++i)
read(p[i]);
std::vector<int> pos(n + 1);
for (int i = 1; i <= n; ++i)
pos[p[i]] = i;
std::array<modint, 4> v{0, 0, 0, n - 1};
modint ans = 0;
for (int k = 2; k <= n; ++k)
{
Matrix mat{};
if (int pre = pos[k - 1] - 1; pre)
{
if (p[pre] >= k)
v[3] -= 1, v[2] += 1;
else
v[1] -= 1, v[0] += 1;
}
if (int suf = pos[k - 1] + 1; suf <= n)
{
if (p[suf] >= k)
v[3] -= 1, v[1] += 1;
else
v[0] += 1, v[2] -= 1;
}
mat.a[0][0] = 1ll * (n - 3) * (n - 2) / 2 + std::max(0, k - 3) * 2 + 1;
mat.a[0][1] = n - k + 1, mat.a[0][2] = n - k + 1;
mat.a[1][0] = k - 2, mat.a[1][1] = 1ll * (n - 3) * (n - 2) / 2 + n - k + k - 2, mat.a[1][2] = 1, mat.a[1][3] = n - k;
mat.a[2][0] = k - 2, mat.a[2][1] = 1, mat.a[2][2] = mat.a[1][1], mat.a[2][3] = n - k;
mat.a[3][0] = 0, mat.a[3][1] = mat.a[3][2] = k - 1, mat.a[3][3] = 1ll * (n - 3) * (n - 2) / 2 + std::max(0, n - k - 1) * 2 + 1;
mat = quick_pw(mat, m);
std::array<modint, 4> res{};
for (int i = 0; i < 4; ++i)
for (int j = 0; j < 4; ++j)
res[i] += v[j] * mat.a[j][i];
ans += res[1] + res[2];
}
printf("%d\n", ans);
return 0;
}
|
第二种解法:
实际上这种可以分拆贡献的题目,一般都直接考虑贡献——即$P[i]$和$P[j]$如何向答案提供贡献。
对于这种交换操作,有一个普适的做法。来源于P4223 期望逆序对。
考虑两个位置$L$和$R$,其数字是$A_{L}$和$A_R$,设其它数字是$A_{other}$。经过交换之后,$L$和$R$上的数字会有七种状态——$(A_L,A_R),(A_L,A_{other}),(A_R,A_L),(A_R,A_{other}),(A_{other},A_L),(A_{other},A_R),(A_{other},A_{other})$。
同样跟解法1一样,写出矩阵$Mat$。
$Mat=\begin{bmatrix}
C_{n-2}^{2}&n-2&1&0&0&n-2&0\
1&C_{n-2}^2+n-3&0&1&1&0&n-3\
1&0&C_{n-2}^2&n-2&n-2&0&0\
0&1&1&C_{n-2}^{2}+n-3&0&1&n-3\
0&1&1&0&C_{n-2}^{2}+n-3&1&n-3\
1&0&0&1&1&C_{n-2}^{2}+n-3&n-3\
0&1&0&1&1&1&C_{n-2}^2+2(n-4)+1\
\end{bmatrix}$
通过初始向量$v=(1,0,0,0,0,0,0)$,$v *= Mat^M$,这样任意两个位置在交换$M$次之后的状态以及对应的方案数都确定了。接下来考虑贡献。
因为这里的贡献只有$P[i]$和$P[i+1]$,考虑在$M$次交换之后,各状态对答案的贡献。
首先最好考虑的就是$(A_L,A_R)$以及$(A_R,A_L)$两个状态的贡献。显然是$(v[0]+v[2])\times|P[i]-P[i+1]|$。对于$(A_{other},A_L)$,因为$A_{other}$有$n-2$种可能,每种可能性出现的次数都是均等的,所以单个可能是$\frac{v[1]}{n-2}$。考虑$f(x)=\sum_{i=1}^N|i-x|$,贡献数是$\frac{v[1]\times[f(P[i])-|P[i]-P[i+1]|]}{n-2}$。接下来的贡献同理。
考虑状态$(A_{other},A_{other})$的贡献数。一共有$(n-2)(n-3)$种均等的可能性。通过枚举第一个$A_{other}$的值,可以得到贡献为$\frac{v[6]\times(\sum_{x=1}^Nf(x)-2f(P[i])-2f(P[i+1])+2|P[i]-P[i+1]|)}{(n-2)(n-3)}$。
最终复杂度为$O(N+7^3log_{2}M)$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
|
#include <atcoder/modint>
using modint = atcoder::modint998244353;
template <class T, int SIZE = 2>
struct Matrix
{
std::array<std::array<T, SIZE>, SIZE> a{};
Matrix(T v = 0)
{
for (int i = 0; i < SIZE; ++i)
a[i][i] = v;
}
Matrix operator*(const Matrix &rhs) const
{
Matrix res{};
for (int i = 0; i < SIZE; ++i)
for (int j = 0; j < SIZE; ++j)
for (int k = 0; k < SIZE; ++k)
res.a[i][j] += a[i][k] * rhs.a[k][j];
return res;
}
std::array<T, SIZE> &operator[](int i)
{
return a[i];
}
const std::array<T, SIZE> &operator[](int i) const
{
return a[i];
}
};
template <class T>
T quick_pw(T a, ll b)
{
static T I{1};
if (b == 0)
return I;
Matrix ans = I, base = a;
while (b)
{
if (b & 1)
ans = ans * base;
b >>= 1;
base = base * base;
}
return ans;
}
int Main()
{
int n, m;
read(n, m);
std::vector<int> p(n + 1);
for (int i = 1; i <= n; ++i)
read(p[i]);
std::vector<int> pos(n + 1);
for (int i = 1; i <= n; ++i)
pos[p[i]] = i;
std::vector<modint> f(n + 1);
f[1] = 1ll * n * (n - 1) / 2;
for (int i = 2; i <= n; ++i)
f[i] = f[i - 1] + i - 1 - (n - i + 1);
modint sum = std::accumulate(f.begin(), f.end(), modint(0));
Matrix<modint, 7> M{};
modint c_n_2_2 = 1ll * (n - 3) * (n - 2) / 2;
modint inv_n_2 = 1, inv_n_3 = 1;
if (n - 2)
inv_n_2 /= (n - 2);
if (n - 3)
inv_n_3 /= (n - 3);
M[0][0] = c_n_2_2, M[0][1] = n - 2, M[0][2] = 1, M[0][5] = n - 2;
M[1][0] = 1, M[1][1] = c_n_2_2 + n - 3, M[1][3] = M[1][4] = 1, M[1][6] = n - 3;
M[2][0] = 1, M[2][2] = c_n_2_2, M[2][3] = M[2][4] = n - 2;
M[3][1] = M[3][2] = 1, M[3][3] = c_n_2_2 + n - 3, M[3][5] = 1, M[3][6] = n - 3;
M[4][1] = M[4][2] = 1, M[4][4] = M[3][3], M[4][5] = 1, M[4][6] = n - 3;
M[5][0] = M[5][3] = M[5][4] = 1, M[5][5] = c_n_2_2 + n - 3, M[5][6] = n - 3;
M[6][1] = M[6][3] = M[6][4] = M[6][5] = 1, M[6][6] = c_n_2_2 + 2 * (n - 4) + 1;
M = quick_pw(M, m);
modint ans = 0;
auto v = M[0];
for (int i = 1; i <= n - 1; ++i)
{
modint diff = std::abs(p[i] - p[i + 1]);
ans += (v[0] + v[2]) * diff;
ans += (v[1] + v[4]) * inv_n_2 * (f[p[i]] - diff);
ans += (v[3] + v[5]) * inv_n_2 * (f[p[i + 1]] - diff);
ans += v[6] * inv_n_2 * inv_n_3 * (sum - 2 * (f[p[i]] + f[p[i + 1]]) + 2 * diff);
}
printf("%d\n", ans);
return 0;
}
int main()
{
int TestCases = 1;
if constexpr (MultiTestCases == 1)
scanf("%d", &TestCases);
while (TestCases--)
Main();
return 0;
}
|
总结一下:新的东西出现了!第一个是切糕模型,这种拆贡献的方式确实厉害了。第二个是这个矩阵的做法,任意且独立的多次操作,状态压缩之后通过矩阵推导最终状态的方案,然后再单独算贡献。相当于把可能性都展现出来,然后只用考虑单次操作对状态的变化(就简单很多),最终利用快速幂来压缩运算。
要去补一下提到的两道题。留个白先。
切糕问题:看了一眼感觉跟这题没啥关系啊,可能他的切糕模型跟那个题不一样吧。这个建模是指在最小割里面怎么添加无穷容量的边的问题;
P4223 期望逆序对:一个排列,每轮任选两个数交换,一共$k$轮,求所有操作序列最终带来的逆序对总和。
就直接从7种状态对答案的贡献开始讨论好了
$(A_L,A_R)$对答案产生贡献,说明原先是一个逆序对;
$(A_R,A_L)$对答案产生贡献,说明原先是一个顺序对;
$(A_{other}, A_L)$对答案产生贡献,那么$A_{other}>A_L$且$A_{other}\neq A_R$。那么对于原先的一个顺序对$(A_L,A_R)$,提供的贡献就是$\frac{N-A_L-1}{N-2}$;对于一个逆序对$(A_L,A_R)$,提供的贡献是$\frac{N-A_L}{N-2}$
$(A_{other}, A_R)$对答案产生贡献,那么$A_{other}>A_R$且$A_{other}\neq A_L$。那么对于原先的一个顺序对$(A_L,A_R)$,提供的贡献就是$\frac{N-A_R}{N-2}$;对于一个逆序对$(A_L,A_R)$,提供的贡献是$\frac{(N-A_R-1)}{N-2}$。
$(A_{L}, A_{other})$对答案产生贡献,那么$A_{other}<A_L$且$A_{other}\neq A_R$。那么对于原先的一个顺序对$(A_L,A_R)$,提供的贡献就是$\frac{A_L-1}{N-2}$;对于一个逆序对$(A_L,A_R)$,提供的贡献是$\frac{A_L-2}{N-2}$
$(A_{R}, A_{other})$对答案产生贡献,那么$A_{other}<A_R$且$A_{other}\neq A_L$。那么对于原先的一个顺序对$(A_L,A_R)$,提供的贡献就是$\frac{A_R-2}{N-2}$;对于一个逆序对$(A_L,A_R)$,提供的贡献是$\frac{A_R-1}{N-2}$
$(A_{other},A_{other})$,产生$\frac{1}{2}$的贡献,且对于每一对数都成立
那么就直接在求顺序对和逆序对的时候直接计算贡献即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
int Main()
{
int n, k;
read(n, k);
std::vector<int> p(n + 1);
for (int i = 1; i <= n; ++i)
read(p[i]);
FenwickTree<int> fwt(n);
modint ans = 0;
Matrix<modint, 7> M{};
modint c_n_2_2 = 1ll * (n - 3) * (n - 2) / 2;
M[0][0] = c_n_2_2, M[0][1] = n - 2, M[0][2] = 1, M[0][5] = n - 2;
M[1][0] = 1, M[1][1] = c_n_2_2 + n - 3, M[1][3] = M[1][4] = 1, M[1][6] = n - 3;
M[2][0] = 1, M[2][2] = c_n_2_2, M[2][3] = M[2][4] = n - 2;
M[3][1] = M[3][2] = 1, M[3][3] = c_n_2_2 + n - 3, M[3][5] = 1, M[3][6] = n - 3;
M[4][1] = M[4][2] = 1, M[4][4] = M[3][3], M[4][5] = 1, M[4][6] = n - 3;
M[5][0] = M[5][3] = M[5][4] = 1, M[5][5] = c_n_2_2 + n - 3, M[5][6] = n - 3;
M[6][1] = M[6][3] = M[6][4] = M[6][5] = 1, M[6][6] = c_n_2_2 + 2 * (n - 4) + 1;
M = quick_pw(M, k);
auto v = M[0];
modint n_2_inv = n - 2 ? modint(n - 2).inv() : 0;
for (int i = 1; i <= n; ++i)
{
modint ord = fwt.query(p[i]), inv = i - 1 - ord;
ans += ord * v[2] + inv * v[0];
ans += inv * (p[i] - 1) * n_2_inv * v[3] + ord * (p[i] - 2) * n_2_inv * v[3];
ans += inv * (n - p[i] - 1) * n_2_inv * v[5] + ord * (n - p[i]) * n_2_inv * v[5];
fwt.modify(p[i], 1);
}
for (int i = 1; i <= n; ++i)
fwt.modify(p[i], -1);
for (int i = n; i >= 1; --i)
{
modint inv = fwt.query(p[i]), ord = n - i - inv;
ans += inv * (p[i] - 2) * n_2_inv * v[1] + ord * (p[i] - 1) * n_2_inv * v[1];
ans += inv * (n - p[i]) * n_2_inv * v[4] + ord * (n - p[i] - 1) * n_2_inv * v[4];
fwt.modify(p[i], 1);
}
ans += 1ll * n * (n - 1) / 2 * modint(2).inv() * v[6];
printf("%d\n", ans);
return 0;
}
|
P.S.:
两种做法差好多啊。。。第一个做法有一个64的常数。但第二个做法写矩阵有点痛苦…

一个$N$个节点的竞赛图,需要有$M$条边是从小编号连到大编号。问所有满足条件的图,强连通分量(SCC)的总数是多少。
$N\leq30, M\leq \frac{N(N-1)}{2}$
竞赛图是把一个完全图的边定向之后的有向图。
这样的话把竞赛图进行SCC缩点,会形成一条链,且每个节点向后续节点都有边。
每个SCC的大小,节点编号都很难确定。直接从SCC的角度考虑很费劲。而且$M$条边从小编号连到大编号这种限制,似乎感觉在告诉我们从小到大加节点,然后给边定向,这样方便满足这个限制。这样的话每次加一个节点,还可能会破坏之前枚举的SCC的链结构。
直接计数很费劲的话,考虑能否构造一一映射。
一个定理:
考虑将图分为两个集合$A$和$B$($B$非空),使得两个集合之间,只有$A$连到$B$的边。竞赛图的SCC个数,等价于这个集合划分方案数。
实际上这个定理是缩链之后的一个引理。因为划分集合的方案,等价于在这条链上按拓扑序一分为二,显然是SCC-1种切分。这样如果$B$不为空$A$可以为空,就恰好是SCC的个数。
这样就可以考虑维护这个$A$集合和$B$集合。枚举$A$集合,每次加一个新节点进来只需要考虑两个决策——节点分在哪个集合中。发现新节点构造边的方案数实际上只跟$A$集合的大小有关,那么压缩$A$集合的状态为枚举大小。
$dp[i][j][k]$表示前$i$个节点,$A$集合大小为$j$,满足条件的边有$k$个。
假设$i+1$分到$A$集合中,首先$i+1$向$B$集合连边,编号从大连到小;剩下的边在$A$集合内部,可以随意连。设有$x$个节点连向$i+1$,则$dp[i+1][j+1][k+x] += dp[i][j][k]\times C_{j}^{x}$
假设$i+1$分到$B$集合中,那么$A$集合所有点向$i+1$连边,编号从小连到大;剩下的边在$B$集合内部,设有$x$个节点连向$i+1$,则$dp[i+1][j][k+j+x] += dp[i][j][k]\times C_{i-j}^{x}$。
最终去掉空集$B$的方案即可;否则,对于每一种可能的图都多加了1,要减去$2^{\frac{N(N-1)}{2}}$。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
#include <atcoder/modint>
using modint = atcoder::modint998244353;
int Main()
{
int n, m;
read(n, m);
std::vector dp(n + 1, std::vector(n + 1, std::vector<modint>(m + 1)));
std::vector C(n + 1, std::vector<modint>(n + 1));
C[0][0] = 1;
for (int i = 1; i <= n; ++i)
{
C[i][0] = 1;
for (int j = 1; j <= i; ++j)
C[i][j] = C[i - 1][j - 1] + C[i - 1][j];
}
dp[0][0][0] = 1;
for (int i = 0; i < n; ++i)
for (int j = 0; j <= i; ++j)
for (int k = 0; k <= m; ++k)
{
if (dp[i][j][k] == 0)
continue;
for (int x = 0; x <= j; ++x)
if (k + x <= m)
dp[i + 1][j + 1][k + x] += dp[i][j][k] * C[j][x];
for (int x = 0; x <= i - j; ++x)
if (k + j + x <= m)
dp[i + 1][j][k + j + x] += dp[i][j][k] * C[i - j][x];
}
modint ans = 0;
for (int i = 0; i < n; ++i)
ans += dp[n][i][m];
printf("%d\n", ans);
return 0;
}
|
总结一下:我是想不出来的…首先这个编号的限制我就没想明白,现在复盘一下觉得这是从小到大加点的一个提示。接下来是这个构造一一映射的过程,这确实计数题的一个比较典型的解法。由于SCC的结构很难用DP状态来表示,构造了这个一一映射,直接简化了问题,而且每个新节点的决策只有两种,太厉害了。感觉有的时候,有一些很冷门的知识点,如果能想到就能解决问题,比如这个竞赛图的集合划分方案,以及之前做过的一个数组LCM的问题——那道题需要知道若干数的最小公倍数的质因数分解中每个因数的指数是数组中该因数的最大指数,当然那道题我想到了,这个状态就可以用一个bitmask来表示。的确有时候需要这种灵感以及知识点,灵感这个东西靠经验,知识点就得靠积累了,多做题肯定是没错的。
一个$N$个节点的图,两个长度为$M$的序列$R$和$B$。每次加边选择$R$和$B$中没被选择的一个,一共有$M!$种加边方法。求所有加边方法,最终形成的连通块数量的期望
$M\leq 10^5, N\leq 17$
因为一共有$M!$种加边法,所有求所有加边法的连通块总数即可。
很自然能想到枚举连通块的点集,为总数做贡献。设点集为$S$的单个连通块的构建方法为$f(S)$,点集$S$在$R$和$B$中各出现了$k$次,显然对总数的贡献是$f(S) * (M-k)!$。
求$f(S)$感觉很困难,此时我想到利用前缀和差分的方式求。但觉得复杂度高弃了真是有点大病。
点集为$S$的点,连边的方案一共是$k!$。取这个点集的一个长度为$l$的子集划分${s_1,…,s_l}$。每一个不同的子集划分,方案是不会有重复的。这样$k! = \sum_{S={s_1,…,s_l}} \prod_{i=1}^{l}f(s_i)$。$f(S)$就等价于长度为1的子集划分。这样可以枚举子集做一个差分,为了避免重复计算,取点集最大编号的那个点所在的集合$s_l$来做。即$f(S)=k!-\sum_{s_l}f(s_l)[\sum_{S-s_l = {s1,…,s_l-1}}\prod_{i=1}^{l-1}f(s_i)]$,后面的显然可以利用前缀和一类的东西来计算子问题。这样就做完了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
#include <atcoder/modint>
using modint = atcoder::modint998244353;
int Main()
{
int n, m;
read(n, m);
std::array<std::vector<int>, 2> a{std::vector<int>(m + 1), std::vector<int>(m + 1)};
for (int p = 0; p < 2; ++p)
for (int i = 1; i <= m; ++i)
read(a[p][i]), a[p][i]--;
std::array<std::vector<int>, 2> cnt{std::vector<int>(n), std::vector<int>(n)};
for (int p = 0; p < 2; ++p)
for (int i = 1; i <= m; ++i)
cnt[p][a[p][i]]++;
std::vector<modint> factor(m + 1);
factor[0] = 1;
for (int i = 1; i <= m; ++i)
factor[i] = factor[i - 1] * i;
std::vector<modint> f(1 << n), g(1 << n);
f[0] = 1;
modint ans = 0;
for (int mask = 1; mask < (1 << n); ++mask)
{
int mx = -1;
std::array<int, 2> tmp{};
for (int i = 0; i < n; ++i)
if (mask & (1 << i))
mx = i, tmp[0] += cnt[0][i], tmp[1] += cnt[1][i];
if (tmp[0] != tmp[1])
continue;
modint all = factor[tmp[0]];
g[mask] = 0;
for (int S = (mask ^ (1 << mx)), T = S; T; T = (T - 1) & S)
g[mask] += g[T] * f[mask ^ T];
f[mask] = all - g[mask];
g[mask] += f[mask];
ans += f[mask] * factor[m - tmp[0]];
}
printf("%d\n", ans / factor[m]);
return 0;
}
|
总结一下:不能因为感觉困难就放弃思考放弃治疗啊!!!明明自己已经整理过反演相关的东西了,为什么放弃治疗了!!
假设有一个长为$N$字符串$X$,给出$M$条限制,每条限制是$X[A_{i},B_i]$在字典序上比$X[C_i,D_i]$小。求是否有这样的字符串。
$N\leq 2000, M\leq 2000$
考虑字典序小,说明可能有一段LCP,然后在$X[A_i+LCP]$和$X[C_i+LCP]$的地方比出大小。一般这种给出$M$条限制的可以按图论考虑。这样就可以利用有向图来刻画“小于”的偏序关系。
维护每个限制的LCP,将当前要比较的一位按偏序连边。如果最终这个图出现了自环或者SCC,说明有当前偏序未能满足,且有部分位置的字符一定是相等的,这时将未能满足的限制的LCP加1,重复这个过程。注意到每次新过程需要保存老过程的SCC,因为需要维护字符的相等,这样每轮的图边数一共有$O(NM)$条,会TLE。实际上老过程的SCC可以直接用DSU缩点,这样每轮的图边数一共有$O(M)$条。另外如果出现了新的SCC,会多跑一轮,一个$N$个节点的图,SCC数量只会从$N$减到1,这样出现新的SCC时,相当于缩点之后的图节点变少了,于是最多跑$N$轮。复杂度是$O(N(N+M))$。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
#include <atcoder/dsu>
std::pair<int, std::vector<int>> Tarjan(std::vector<std::vector<int>> &G, int n)
{
std::vector<int> dfn(n + 1), low(n + 1), scc(n + 1);
std::stack<int> stack;
std::vector<bool> ins(n + 1);
int stamp = 0, cnt = 0;
std::function<void(int)> tarjan = [&](int u)
{
// int t, minc = low[v] = pre[v] = cnt++;
stack.push(u), ins[u] = true;
dfn[u] = low[u] = ++stamp;
for (int v : G[u])
{
if (!dfn[v])
{
tarjan(v);
low[u] = std::min(low[v], low[u]);
}
else if (ins[v])
low[u] = std::min(low[u], dfn[v]);
}
if (dfn[u] != low[u])
return;
cnt++;
int t = 0;
do
{
ins[t = stack.top()] = false;
scc[t] = cnt;
stack.pop();
} while (t != u);
};
for (int i = 1; i <= n; ++i)
if (!dfn[i])
tarjan(i);
return {cnt, scc};
}
int Main()
{
int n, m;
read(n, m);
std::vector<std::array<int, 5>> e(m + 1);
for (int i = 1; i <= m; ++i)
{
auto &[a, b, c, d, lcp] = e[i];
read(a, b, c, d);
lcp = 0;
}
std::vector adj(n + 1, std::vector<int>{});
atcoder::dsu dsu(n + 1);
while (true)
{
for (int i = 1; i <= n; ++i)
adj[i].clear();
bool self_loop = false;
for (int i = 1; i <= m; ++i)
{
auto [a, b, c, d, lcp] = e[i];
int u = a + lcp, v = c + lcp;
if (u > b)
continue;
u = dsu.leader(u), v = dsu.leader(v);
adj[u].push_back(v);
self_loop |= (v == u);
}
auto [cnt, scc] = Tarjan(adj, n);
if (cnt == n && !self_loop)
return printf("Yes\n"), 0;
for (int i = 1; i <= m; ++i)
{
auto &[a, b, c, d, lcp] = e[i];
int u = a + lcp, v = c + lcp;
if (u > b)
continue;
u = dsu.leader(u), v = dsu.leader(v);
if (scc[u] == scc[v])
lcp++, dsu.merge(u, v);
if (lcp == d - c + 1)
return printf("No\n"), 0;
}
}
printf("No\n");
return 0;
}
|
总结一下:我自己分析出来了,有点开心,这里有点后缀数组倍增的意思,实际上考虑LCP是字典序的典型解法。然后复杂度分析那块稍微卡住了,但是考虑了一下缩点,这样每轮甚至轮数都确定了,还是挺妙的。
在一行里有$N$个方格,有$M$种操作$L_i$和$R_i$,表示将$[L_i,R_i]$这个区间全染黑;如果这个区间已经黑了就不能染了。问最多能进行几次操作。
$N\leq500$
这个数据类型就挺区间DP的。然后考虑$dp[l][r]$表示$[l,r]$区间最多进行几次操作,注意这里所有的操作都不能超过$[l,r]$。然后就是枚举最后一个染黑的点$mid$,这个点目前是白的,所以之前的操作都不会越过$mid$,归约到子问题$dp[l][mid-1]$和$dp[mid+1][r]$。当然这个点能操作当且仅当在$[l,r]$中包含一个能染$mid$的操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
int Main()
{
int n, m;
read(n, m);
std::vector<std::pair<int, int>> a(m + 1);
for (int i = 1; i <= m; ++i)
{
auto &[l, r] = a[i];
read(l, r);
}
std::sort(a.begin() + 1, a.end());
std::vector dp(n + 1, std::vector<int>(n + 1, 0));
for (int i = 1; i <= m; ++i)
if (auto [l, r] = a[i]; l == r)
dp[l][r] = 1;
std::vector ok(n + 1, std::vector(n + 1, std::vector<int>(n + 1)));
for (int i = 1; i <= n; ++i)
{
for (int j = 1; j <= m; ++j)
{
auto [l, r] = a[j];
if (l <= i && r >= i)
ok[i][l][r] = 1;
}
for (int l = n; l >= 1; --l)
for (int r = 1; r <= n; ++r)
{
if (l - 1 >= 1)
ok[i][l - 1][r] |= ok[i][l][r];
if (r + 1 <= n)
ok[i][l][r + 1] |= ok[i][l][r];
if (l - 1 >= 1 && r + 1 <= n)
ok[i][l - 1][r + 1] |= ok[i][l][r];
}
}
for (int len = 2; len <= n; ++len)
for (int l = 1; l <= n; ++l)
{
int r = l + len - 1;
if (r > n)
break;
for (int mid = l; mid <= r; ++mid)
if (ok[mid][l][r])
dp[l][r] = std::max(dp[l][r], ((l <= mid - 1) ? dp[l][mid - 1] : 0) + ((mid + 1 <= r) ? dp[mid + 1][r] : 0) + 1);
}
std::cout << dp[1][n] << std::endl;
return 0;
}
|
总结一下:挺直觉的,但是国外给的难度评级比较高,难道区间DP是CN强项?当然如果要很严谨地证还是有点复杂。
假设一棵以1为根的有根树有$N$个节点,每个节点的出度是$d_i$。
求所有这样的树里面,子树的根节点是子树编号最小的那个点,这样的点的总数。
$N\leq500$
一开始看到是有根树的感觉有点复杂,后来一看以1为根,那不就是无根树的数量。
给出每个点的出度,即意味着除了根节点外每个点度数$deg_i$都是$d_i+1$。给出点度数求树的数量,显然Prufer序列。在$N-2$个格子里面,点$i$出现了$deg_i-1$次。方案就是多重组合数$\frac{(N-2)!}{\prod_{i=1}^N(deg_i-1)!}$。原来出度是为了让我们不用减1了?Atcoder你人还怪好的。
然后考虑一个节点$v$作为根的时候是子树编号最小的点。发现这样的话就相当于从$[v+1,N]$里面拿一些节点凑成一个子树。显然$v$子树有若干形状,而$v$子树外面也有若干形状。假设拿取的点是$t_1,…t_k$。于是$v$子树的方案有$\frac{(k-1)!}{\prod_{i=1}^k(d_{t_i}!)\times (d_v-1)!}$,$v$子树外的方案相当于把$v$子树当做一个叶子,再凑成一个新树,方案是$\frac{(N-k-2)!}{\prod_{i=2}^{N}[i \notin t]d_i! \times (d_1-1)!}$。这俩乘在一起,发现分母就是算树总数的那个分母,只不过少乘了一个$d_v$。就是$\frac{(k-1)!(N-k-2)!d_v}{\prod_{i=2}^{N}(d_i)! \times (d_1-1)!}$。于是分母就能预处理出来。分子发现只跟$k$有关。
接下来考虑如何从$[v+1,N]$里面拿子树。显然点度数的和要符合条件,一个大小为$k$的子树,节点的出度和应为$k-1$。又因为不管我们怎么取子树,上面式子的分母都是一样的,所以求一个方案数当做系数就行了。因此相当于做一个背包,$dp[i][j][k]$表示在$[i,N]$里面拿取$j$个节点,度数和为$k$的方案,按01背包去做就行了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
int Main()
{
int N;
read(N);
std::vector<int> d(N + 1);
for (int i = 1; i <= N; ++i)
read(d[i]);
Combinatorics<modint> combinatorics(N);
std::vector dp(N + 2, std::vector(N + 1, std::vector<modint>(N + 1, 0)));
dp[N + 1][0][0] = 1;
// (S-2)!/(d[i]!)*(d[v]-1)! * (N-S-2)!/(d[j]!)*(d[1]-1)!
modint frac = 1;
for (int i = 2; i <= N; ++i)
frac *= combinatorics.invfac[d[i]];
frac *= combinatorics.invfac[d[1] - 1];
modint ans = combinatorics.fac[N - 2] * frac;
for (int i = N; i >= 2; --i)
{
if (d[i] == 0)
ans += combinatorics.fac[N - 2] * frac;
else
{
for (int j = d[i] + 1; j <= N - i + 1; ++j)
ans += dp[i + 1][j - 1][j - 1 - d[i]] * frac * d[i] * combinatorics.fac[j - 2] *
((N - j - 1 >= 0) ? combinatorics.fac[N - j - 1] : 1);
}
for (int j = 0; j <= N - i + 1; ++j)
for (int k = 0; k <= N - 1; ++k)
{
dp[i][j][k] += dp[i + 1][j][k];
if (j >= 1 && k >= d[i])
dp[i][j][k] += dp[i + 1][j - 1][k - d[i]];
}
}
printf("%d\n", ans);
return 0;
}
|
总结一下:最近看房子,没有很认真地用纸笔推演。甚至一开始看错题了怎么都做不出来。最终在脑子里大致推出来一个型,虽然那个型没考虑$v$子树外的情况,但好在在洗碗的时候意识到了…全程意识流,感觉Prufer序列处理点度数问题是一个经典思路,我也是从那道生成函数里学到的。感觉多做难题会学会很多知识点?按质因数状态做容斥也是在一个CF 3000分左右的题里面学到的。是不是应该考虑加大平时做题难度了呢。
ABC248G.GCD cost on the tree
一棵$N$个节点的树,点$i$的点权为$a[i]$。
一条从$u$到$v$的路径权值被定义为路径上点权的GCD和路径点数的乘积。
求这棵树所有路径的权值和。$N\leq 10^5, a[i]\leq 10^5$
这种关于多个节点GCD相关的题目,一般来说可以考虑枚举公共约数$d$,这样抽出部分节点,直接求解。接下来做一步差分或者叫容斥。设公共约数为$d$的问题答案为$f(d)$,则最大公约数为$d$的问题答案为$g(d)=f(d)-\sum_{i=2}^{i * d\leq N}g(i*d)$。这一步复杂度为调和级数。
对于这道题目也是一样的,假设约数为$d$的节点形成的森林$F$,对于这个$F$求出路径长度的和$f(d)$,然后求一下$g(d)$,最后$g(d)*d$加到答案上。
复杂度的话,对于每个$a[i]$,约数最多大概是200个左右。那么所有森林的节点和为$200 * N$,配合8s的时限可以接受。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
#include <atcoder/modint>
using modint = atcoder::modint998244353;
int Main()
{
int n;
read(n);
std::vector<int> a(n + 1);
for (int i = 1; i <= n; ++i)
read(a[i]);
int mx = *std::max_element(a.begin(), a.end());
std::vector b(mx + 1, std::vector<int>{});
for (int i = 1; i <= n; ++i)
{
for (int j = 1; j * j <= a[i]; ++j)
{
if (a[i] % j)
continue;
b[j].push_back(i);
if (a[i] / j != j)
b[a[i] / j].push_back(i);
}
}
std::vector G(mx + 1, std::vector<std::pair<int, int>>{});
for (int i = 1; i <= n - 1; ++i)
{
int u, v;
read(u, v);
int gcd = std::gcd(a[u], a[v]);
for (int j = 1; j * j <= gcd; ++j)
if (gcd % j == 0)
{
G[j].emplace_back(u, v);
if (gcd / j != j)
G[gcd / j].emplace_back(u, v);
}
}
std::vector<modint> f(mx + 1);
std::vector<int> size(n + 1);
std::vector adj(n + 1, std::vector<int>{});
std::function<void(int, int)> dfs1 = [&](int u, int fa)
{
size[u]++;
for (int v : adj[u])
if (v != fa)
dfs1(v, u), size[u] += size[v];
};
std::function<modint(int, int, int)> dfs2 = [&](int u, int fa, int cnt)
{
modint res = 0;
for (int v : adj[u])
if (v != fa)
{
res += 1ll * size[v] * (cnt - size[v]);
res += dfs2(v, u, cnt);
}
return res;
};
for (int j = 1; j <= mx; ++j)
{
if (b[j].size() == 0)
continue;
for (auto [u, v] : G[j])
adj[u].push_back(v), adj[v].push_back(u);
for (int u : b[j])
if (size[u] == 0)
{
dfs1(u, 0);
f[j] += 1ll * size[u] * (size[u] + 1) / 2;
f[j] += dfs2(u, 0, size[u]);
}
for (int u : b[j])
size[u] = 0;
for (auto [u, v] : G[j])
adj[u].clear(), adj[v].clear();
}
modint ans = 0;
for (int d = mx; d >= 1; --d)
{
for (int i = 2; i * d <= mx; ++i)
f[d] -= f[i * d];
ans += f[d] * d;
}
ans -= std::accumulate(a.begin(), a.end(), modint(0));
printf("%d\n", ans);
return 0;
}
|
总结一下:套路缝合怪。重点在于多个点的最大公约数,枚举公共约数然后做差分这一步。
ARC127D.Sum of Min of Xor
有两个长度为$N$的序列$A$和$B$。
求$\sum_{i=1}^{N} \sum_{j=1}^{i-1} min(A_i \oplus A_j, B_i \oplus B_j)$
$N\leq 250000$
$A[i] < 2^{18}, B[i] < 2^{18}$
同一种技巧在CF1720D2。对于那道题目就是$a[i]\oplus j > a[j] \oplus i$。像这种交叉型的,考虑第一个出现差异的位。那么这一位之前都是相等的,就是说$a[i] \oplus j = a[j] \oplus i$,也就等价于$a[i] \oplus i = a[j] \oplus j$。于是这样就不交叉了。就可以在$a[j] \oplus j$组成的Trie树里面操作了。当出现不同的位的时候分类讨论一下。
对于这道题,在出现不同的位的时候,直接计算对应的异或和。相当于问题变成在一棵树的子树里面有一堆数字,求这堆数对$a[i]$的异或值的和。
显然是经典问题,统计每一位01的数量即可。因此在$A[i] \oplus B[i]$的Trie树上做这样的操作。当出现有差异的位时,去计算异或值的和。
复杂度是$O(Nlog^2A)$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
struct XORTrie
{
struct Info
{
std::array<int, 18> a_cnt{}, b_cnt{};
int tot = 0;
};
struct node
{
std::array<int, 2> trans{};
int cnt;
std::array<Info, 2> info{};
int &operator[](int i)
{
return trans[i];
}
};
std::vector<node> trie;
int n, cnt = 0;
XORTrie(int _n) : n(_n), trie(std::min(1 << 19, _n * 18) + 1)
{
}
void insert(int a, int b)
{
int p = 0;
int x = a ^ b;
for (int i = 17; i >= 0; --i)
{
int bit = (x & (1 << i)) > 0;
if (!trie[p][bit])
trie[p][bit] = ++cnt;
p = trie[p][bit];
bit = (a & (1 << i)) > 0;
for (int j = 0; j < i; ++j)
{
int abit = (a & (1 << j)) > 0;
int bbit = (b & (1 << j)) > 0;
trie[p].info[bit].a_cnt[j] += abit;
trie[p].info[bit].b_cnt[j] += bbit;
}
trie[p].info[bit].tot++;
}
}
ll query(int a, int b)
{
int c = a ^ b;
int p = 0;
ll res = 0;
for (int i = 17; i >= 0; --i)
{
int abit = (a & (1 << i)) > 0;
int bbit = (b & (1 << i)) > 0;
int cbit = abit ^ bbit;
if (int tmp = trie[p][cbit ^ 1]; tmp)
{
const Info &ainfo = trie[tmp].info[abit], &binfo = trie[tmp].info[abit ^ 1];
for (int j = 0; j < i; ++j)
{
int ajbit = (a & (1 << j)) > 0;
int bjbit = (b & (1 << j)) > 0;
if (ajbit)
res += (1ll << j) * (ainfo.tot - ainfo.a_cnt[j]);
else
res += (1ll << j) * ainfo.a_cnt[j];
if (bjbit)
res += (1ll << j) * (binfo.tot - binfo.b_cnt[j]);
else
res += (1ll << j) * binfo.b_cnt[j];
}
}
if (int nxt = trie[p][cbit]; nxt)
{
res += (1ll << i) * trie[nxt].info[abit ^ 1].tot;
p = nxt;
}
else
break;
}
return res;
}
};
int Main()
{
int N;
read(N);
std::vector<int> A(N + 1), B(N + 1);
std::for_each(A.begin() + 1, A.end(), read<decltype(A[0])>);
std::for_each(B.begin() + 1, B.end(), read<decltype(B[0])>);
XORTrie trie(N);
ll ans = 0;
for (int i = 1; i <= N; ++i)
{
ans += trie.query(A[i], B[i]);
trie.insert(A[i], B[i]);
}
std::cout << ans << std::endl;
return 0;
}
|
总结一下:思路上没啥问题,很自然。写起来分类讨论那段稍微有点费劲。
然后遇到一个坑:正常插入一个高度为$H$的Trie树,可能会认为空间复杂度是$O(N * H)$。而这棵树其实最多有$2^{H+1}$个节点,不能盲目去开$O(N * H)$的空间。

血泪史,有血有泪,还有屎
ARC180D.Division into 3
给一个长为$N$的序列$A$,每次查询给出一个区间$[L,R]$,需要把这个$[L,R]$分为三段,每段取最大值加起来求和,求这个最小的和是多少。一共$Q$次查询。
$N \leq 250000, Q \leq 250000$
首先这个三段中,整个区间$[l,r]$的最大值肯定在这里面。假设这三段为别是$L, M, R$。每段都不为空。
假设最大值$mx$在$M$,那么显然$L$提供的值$max(L) \geq a[l]$,$max(R) \geq a[r]$。那么不如只取两边各一个元素。
然后考虑$mx$在$L$中。假设位置是$p$。对于两段$M$和$R$,假设枚举$max(R)$,求出对应的最小的$M$。想象有一根线,从$r$开始向左滑动,发现对于这根线来说,最小的$M$其实就是线左边那个单独的元素。所以相当于是$a_i +max_{j=i+1}^{r}(a_j)$。发现后面那个值跟$r$有关。不妨扫描线这个$r$,更新这个值,这个过程就是单调栈。最终可以找到$a[r]$能作为最大值的那个区间$[k,r]$,则对于$[k,r-1]$中所有的$i$,$a[i]+a[r]$都是可选的值。懒标记线段树就可以更新这个值。接下来对于一个询问,最大值在$p$,查询$[p+1,r-1]$里的最小值和$a[p]$去更新答案。注意到如果最大值有多个,应该去最小的$p$而不是最大的$p$。因为这根线的滑动范围只有一个最小的限制,如果取最大的$p$,有的$M$和$R$就取不到了。
对于$mx$在$R$里面,是镜像的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
int Main()
{
int n, q;
read(n, q);
std::vector<std::array<int, 3>> info(n + 1);
std::vector<int> a(n + 1);
for (int i = 1; i <= n; ++i)
{
read(a[i]);
info[i] = {a[i], i, i};
}
struct Merge
{
std::array<int, 3> operator()(const std::array<int, 3> &lhs, const std::array<int, 3> &rhs) const
{
std::array<int, 3> res{};
if (lhs[0] == rhs[0])
res[0] = lhs[0], res[1] = lhs[1], res[2] = rhs[2];
else if (lhs[0] > rhs[0])
res = lhs;
else
res = rhs;
return res;
}
};
SparseTable<std::array<int, 3>, Merge> st(info, n);
std::vector<std::vector<std::array<int, 2>>> qry(n + 1), invqry(n + 1);
std::vector<int> ans(q + 1, std::numeric_limits<int>::max());
for (int i = 1; i <= q; ++i)
{
int l, r;
read(l, r);
auto [mx, _, __] = st.query(l, r);
if (auto [mx1, _, __] = st.query(l + 1, r - 1); mx1 == mx)
ans[i] = std::min(ans[i], mx + a[l] + a[r]);
if (auto [mx1, L, R] = st.query(l, r - 2); mx1 == mx)
qry[r].push_back({L + 1, i});
if (auto [mx1, L, R] = st.query(l + 2, r); mx1 == mx)
invqry[n - l + 1].push_back({n - R + 2, i});
}
auto solve = [&]()
{
std::stack<int> stack;
std::vector<Info> init(n + 1);
for (int i = 1; i <= n; ++i)
init[i] = {a[i]};
LazySegmentTree<Info, Tag> segment_tree(init, n);
a[0] = std::numeric_limits<int>::max();
stack.push(0);
for (int r = 1; r <= n; ++r)
{
while (stack.size() && a[stack.top()] <= a[r])
{
int R = stack.top();
stack.pop();
int L = stack.top();
L = std::max(L, 1);
if (L <= R - 1)
segment_tree.apply(L, R - 1, {-a[R]});
}
int pre = stack.top();
segment_tree.apply(std::max(pre, 1), r - 1, {a[r]});
stack.push(r);
for (auto [l, i] : qry[r])
{
auto [sum] = segment_tree.query(l, r - 1);
ans[i] = std::min(ans[i], a[l - 1] + sum);
}
}
};
solve();
std::reverse(a.begin() + 1, a.end());
qry = invqry;
solve();
for (int i = 1; i <= q; ++i)
printf("%d\n", ans[i]);
return 0;
}
|
总结一下:这个题其实做法很多的,也可以这样做:假设$f[i]$是$[i,r]$里划分两段的最大值的最小和,可以发现这两段要么是$[i,i][i+1,r]$,要么就是$[i,r-1][r,r]$。这样感觉维护一个$f[i]$然后用$a[r]$更新一下就行了。以及细节很多:首先$L,M,R$都是非空,那么最大值在$M$中,要用$[l+1,r-1]$的最大值和$[l,r]$的最大值比较一下,其它讨论是类似的。
所以关键在于能识别出来讨论最大值到底在哪这一步,我做到了。但是后面的没太细琢磨,感觉做法很多有点乱。
接着就是对于多个最大值到底选哪一个。我一直以为备选区间越短越好,但实际上我们只是能确定最大值一定在其中一个段(比如$L$里),剩下的实际上越长,备选越多,肯定不会错。假设是这种序列,$a+1,a+1,a+1,a,a+1,a+1,a+1$。如果多个最大值选了最大那个,剩下只有两个$a+1$,而实际上可以是$a$和$a+1$。这是我的一个坑点。
ABC212H.Nim Counting
一个简单的取石子游戏,每人选一堆石子取一个或多个,不能取的人输掉。
现在有一个长度为$K$数组$A$,这个取石子游戏初始每一堆石子都得是$A$里面的一个数。对于所有不超过$N$堆石子的游戏,问先手必胜的游戏数量有多少。
首先对于这种Nim游戏,先手必胜就是每堆石子$SG$函数的异或和不为0。由先验知识得到,最简单的这种取石子游戏$SG[i] = i$。那么题目问的就是不超过$N$个$A$中的数异或起来有多少种情况不为0。
听起来挺OGF的。单堆石子的生成函数为$F(x)=\sum_{i=1}^K(x^{A[i]})$。如果求的是加起来有多少种情况不为0,那么显然就是这个OGF的一个幂次。而这里是异或起来的情况不为0,相当于做异或卷积的幂次。
即$\sum_{i=1}^M([x^i]\sum_{p=1}^N F(x)^{p})$。其中$M$是异或值域。
位运算卷积考虑快速沃尔什变换。由于沃尔什变换是线性变换,那么首先
$[x^i]FWT(\sum_{p=1}^N F(x)^{p})=\sum_{p=1}^N[x^i]FWT(F(x)^p)$;结果的第$i$项是OGF的幂次变换后第$i$项的和。
又有$[x^i]FWT(F(x)^p)=([x^i]FWT(F(x)))^p$;OGF的$p$次幂变换后第$i$项等于OGF变换后第i项的$p$次幂。
把两个式子搞到一块去就发现是
$[x^i]FWT(\sum_{p=1}^N F(x)^{p})=\sum_{p=1}^N([x^i]FWT(F(x)))^p=\frac{F[i](1 - F[i]^{N+1})}{1-F[i]}$等比数列求和。
这样得到了沃尔什变换后的多项式,逆变换回去就可以了。
时间复杂度$O((K+M)log_2M+Mlog_2N)$。其中$M$是异或值域。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
using modint = atcoder::modint998244353;
using FWT = FastWalshHadamardTransform<modint, std::__bitwise_xor>;
int Main()
{
int n, k;
read(n, k);
std::vector<int> a(k + 1);
for (int i = 1; i <= k; ++i)
read(a[i]);
int mx = *std::max_element(a.begin(), a.end());
int bits = std::log2(mx) + 1;
mx = 1 << bits;
std::vector<modint> f(mx);
for (int i = 1; i <= k; ++i)
f[a[i]] += 1;
FWT::dft(f);
for (int i = 0; i < mx; ++i)
{
if (f[i] == 1)
f[i] = n;
else
f[i] = (f[i] - f[i].pow(n + 1)) / (modint{1} - f[i]);
}
FWT::idft(f);
modint ans = std::accumulate(f.begin() + 1, f.end(), modint(0));
printf("%d\n", ans);
return 0;
}
|
总结:新知识点:快速沃尔什变换;FFT和FWT是线性变换,绝大部分的题目,要用到这一点:先按FWT变换之后的线性性质,变成点乘或者点加,再把结果IFWT回去。
ABC367G.Sum of (XOR^K or 0)
在一个长度为$N$的数组$A$中,选择一些非空子序列,这些子序列的长度都是$M$的倍数。
一个子序列的价值为子序列异或和的$K$次幂。求所有合法子序列的价值和。$N,K\leq 2\times10^5,M\leq100,A[i]<2^{20}$。
先考虑没有$M$的倍数这一限制怎么做。显然拿到每个异或和的出现次数,问题就迎刃而解。
可以用OGF来刻画取子序列的过程:$\prod_{i=1}^N(1+x^{A[i]})$,乘法为异或卷积。注意去除空序列。
那么如何快速计算这个OGF的连乘?
注意到$x^{A[i]}$的系数恒为1,由于异或卷积的性质,$(1+x^{A[i]})$在FWT之后的式子中,对于每一项$p$,要么提供$(1+1)$的系数,要么提供$(1-1)$的系数。
单独拿来一个项$p$,有若干个$i$提供了2的系数,有若干个$i$提供了0的系数,假设两者$i$的数量分别为$c_0,c_1$。那么显然$c_0+c_1=n$。我们要求的点乘之后的系数就是$2^{c_0}$。
现在根据点加,$FWT(\sum_{i=1}^N(1+x^{A[i]}))=\sum_{i=1}^N FWT(1+x^{A[i]})$。对于第$p$项,显然FWT点加之后的系数是$2c_0$。这样算一下$FWT(\sum_{i=1}^N(1+x^{A[i]}))$就求解了每一项$p$的$c_0$,进而能得到点乘式的系数。
回到原问题,由于要考虑子序列长度的限制,设一个二元普通生成函数$F_i(x,y)=(1+x^{A[i]}y)$。
这样求解的就是$\prod_{i=1}^N(1+x^{A[i]}y)$,其中在$x$这一维做异或卷积,在$y$这一维做加法取模卷积。最终要找这个式子中所有$x^py^0$的系数。
依然用上述思路考虑。
$(1+x^{A[i]}y)$在FWT之后的式子中,对于每一项$p$,要么提供$(1+y)$的系数,要么提供$(1-y)$的系数。同样设前者的$i$有$c_0$个,后者有$c_1$个。
而由点加,$y$前面的系数就是$c_0-c_1$。于是点乘式可以写成$(1+y)^{c_0}(1-y)^{n-c_0}$。
对于加法取模卷积,注意到只有不超过100项。那么可以用背包DP预处理$(1+y)^i$和$(1-y)^i$。最终对每个$(1+y)^i(1-y)^{n-i}$单独求一下$y^0$的系数$y0[i]$,即可全部预处理。然后做FWT,对每一项$p$求解$c_0$,拿到$y0[c_0]$,$y^0$这一维的点乘式$F’$的系数;最终所求就是$F=FWT(F’)$
枚举每一项,按答案所求加个权就行了。注意没有空序列。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
int Main()
{
int N, M, K;
read(N, M, K);
std::vector<int> a(N + 1);
for (int i = 1; i <= N; ++i)
read(a[i]);
std::array<std::vector<std::vector<modint>>, 2> dp{};
dp.fill(std::vector(N + 1, std::vector<modint>(M)));
dp[0][0][0] = dp[1][0][0] = 1;
for (int k = 0, p = mod - 1; k < 2; ++k)
{
p = 1ll * p * (mod - 1) % mod;
// printf("%d\n", p);
for (int i = 1; i <= N; ++i)
{
for (int j = 0; j < M; ++j)
dp[k][i][j] = dp[k][i - 1][j] + dp[k][i - 1][(j - 1 + M) % M] * p;
}
}
std::vector<modint> y0(N + 1);
for (int i = 0; i <= N; ++i)
{
//(1 + y) ^ i * (1 - y) ^ (N - i)
for (int j = 0; j < M; ++j)
y0[i] += dp[0][i][j] * dp[1][N - i][(M - j) % M];
}
//(1 + x ^ a[i] * y)
constexpr int B = 20;
std::vector<int> diff(1 << B);
for (int i = 1; i <= N; ++i)
diff[a[i]]++;
FWTXor<int>::dft(diff);
std::vector<modint> f(1 << B);
for (int i = 0; i < diff.size(); ++i)
{
// a + b = n, a - b = diff[i]
int x = (N + diff[i]) / 2;
f[i] = y0[x];
}
FWTXor<modint>::idft(f);
f[0] -= 1;
modint ans = 0;
for (int i = 0; i < f.size(); ++i)
ans += f[i] * modint{i}.pow(K);
printf("%d\n", ans);
return 0;
}
|
总结:把上一题的技巧扩展到二元,同样求解方程式。思路依然可以先易后难,递进式思考。对于二元卷积,相当于第一维卷积之后再对另一维卷积,多元同理。
ARC165E.Random Isolation
有一棵$N$个节点的树。
每次随机选一个大于$K$个节点的连通块中的某一个节点,删掉这个节点及相连的边,直到没有可以选中的节点为止。
求这个操作数的期望。
$N\leq 100$
首先多个点,每个点只操作一次;设$X_i$表示$i$节点的操作数,显然$X_i={0或1}$。要求的就是$E(\sum_{i=1}^NX_i)$。由期望的线性性,这个式子等价于$\sum_{i=1}^NE(X_i)$。这样就把贡献单独拆到每个点上了。
由于有的节点可以选有的节点可以不选,那么对于每个节点它被选中的概率是不方便计算的。
有一个套路是假想存在一个排列$P$,按照$P$的顺序来操作,如果遇到了不合法的节点就跳过。这样和原问题是等价的。
至于原因可以这样考虑。
不考虑不合法的节点,假设局面当前局面是$s$,后续合法决策有$m$个,每个决策对应的新局面是$t_i$。
这样局面$s$的操作期望就是$E(s)=\sum_{i=1}^m\frac{1}{m}E(t_i)+1$。
那么当考虑了不合法操作之后,假设有$n$个不合法操作,因为不合法操作不改变当前局面所以是
$E(s)=\frac{n}{n+m}E(s)+\sum_{i=1}^m\frac{1}{n+m}E(t_i)+\frac{m}{n+m}$。
移项之后会发现是一样的。
所以这样做是等价的。
那么这样考虑在一个排列里面为什么$P_i$这个数会带来贡献。当且仅当$P_i$这个数所在的连通块的大小超过$k$。假设这个连通块大小为$s$;那么之所以出现了这个$s$大小的连通块,一定是前面删去了若干个和这个连通块相连的若干点设为$d$。所以一个大小为$s$的连通块,缩点之后如果度数为$d$,这个连通块的在排列中出现的概率是$\frac{d!s!}{(d+s)!}$,因为先要出现$d$个被删的点在前面,然后后面再出现$s$个本连通块里的点,所以对期望的贡献也是$\frac{d!s!}{(d+s)!}$。因此只要统计这个$(s,d)$类型的连通块的数量就行。
这就转化到树上DP了。树上背包做转移就行。
这里还涉及到一个树上背包按子树$size$做背包容量的复杂度计算。
假设树上背包,节点$u$的前$i$个节点,考虑$s$个节点的背包方程$f[u][i][s]$,枚举子树$v$的容量$t$做转移的时候,$f[u][i][s]=merge(f[u][i-1][s-t],dp[v][t])$。这里面首先要枚举一个$i$,$s$和$t$,看起来是$O(n^3)$的复杂度。但实际上$s$枚举大小如果按点$u$已知的$size$实时更新,复杂度是$O(n^2)$。
大概是这样写
1
2
3
4
5
6
7
8
9
|
size[u] = 1;
for (int i = 1; i <= adj[u].size(); ++i)
{
int v = adj[u][i-1];
for (int s = 1; s <= size[u]; ++s)
for (int t = 1; t <= size[v];++t)
f[u][i][s+t] = merge(f[u][i-1][s],dp[v][t]);
size[u]+=size[v];
}
|
至于原因。可以这样想象。每次子树$v$合并的时候,是向前$i-1$个子树里面所有节点合并,等价于把子树$v$里面的节点和前$i-1$个子树的里面的节点配对做节点对,每个节点向dfs序在自己前面的节点配对,最终能配出$O(n^2)$个节点对,因此总复杂度是$O(n^2)$。
那么这样整个复杂度就是$O(N^4)$,完全可以通过,甚至跑的相当快。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
int Main()
{
int n, k;
read(n, k);
std::vector adj(n + 1, std::vector<int>{});
for (int i = 1; i < n; ++i)
{
int u, v;
read(u, v);
adj[u].push_back(v), adj[v].push_back(u);
}
std::vector dp(n + 1, std::vector(n + 1, std::vector<modint>(n + 1)));
std::vector size(n + 1, 1);
auto dfs = [&](auto &&self, int u, int fa) -> void
{
if (fa != 0)
adj[u].erase(std::find(adj[u].begin(), adj[u].end(), fa));
for (int v : adj[u])
self(self, v, u);
std::vector f(adj[u].size() + 1, std::vector(n + 1, std::vector<modint>(n + 1)));
f[0][1][0] = 1;
for (int i = 1; i <= adj[u].size(); ++i)
{
int v = adj[u][i - 1];
for (int s = 1; s <= size[u]; ++s)
for (int d = 1; d <= size[u]; ++d)
f[i][s][d] = f[i - 1][s][d - 1];
for (int s = 1; s <= size[u]; ++s)
for (int t = 1; t <= size[v]; ++t)
{
for (int d = 0; d <= size[u]; ++d)
for (int c = 0; c <= size[v]; ++c)
f[i][s + t][d + c] += f[i - 1][s][d] * dp[v][t][c];
}
size[u] += size[v];
}
for (int s = 1; s <= size[u]; ++s)
for (int d = 0; d <= size[u]; ++d)
dp[u][s][d] += f[adj[u].size()][s][d];
// for (int s = 1; s <= size[u]; ++s)
// for (int d = 0; d <= size[u]; ++d)
// {
// printf("dp[%d][%d][%d] = %d\n", u, s, d, dp[u][s][d]);
// }
};
dfs(dfs, 1, 0);
Combinatorics<modint> combinatorics(n);
modint ans = 0;
for (int i = 1; i <= n; ++i)
for (int s = k + 1; s <= size[i]; ++s)
for (int d = 0; d <= size[i]; ++d)
{
if (dp[i][s][d] != 0)
ans += dp[i][s][d] * combinatorics.fac[s] * combinatorics.fac[d + (i != 1)] * combinatorics.invfac[s + d + (i != 1)];
}
printf("%d\n", ans);
return 0;
}
|
总结:新技巧get!按局面算期望,生成操作排列,这样把整体的概率计算转移到了局部上,进行分析之后再DP。适合经过几轮操作之后,有的操作合法有的操作不合法的期望计算。
ARC150D.Removing Gacha
有一棵$N$个节点的树,树上节点一开始是白色。
如果一个节点$i$到1的路径上全是黑色的点,那么这个点是好点;否则是坏点
现在每次随机地从坏点中选一个点来染成黑色。问把整棵树都染黑的期望数。
$N\leq2\times10^5$
相比于上面那道题,这道题相当于取完球之后放回,操作序列是无穷长度的。
同样考虑一个操作序列,首先点$i$产生贡献当且仅当$1->i$的路径上所有点没出现全。这样在这个序列里我们只关心这条路径。
设$i$的深度为$dep_i$。
那么相当于有放回地取$dep_i$个球,直到所有球都取了一遍,选中$i$的期望次数。
可以写出一个DP。一般期望DP是倒推的。
假设有$n$个球,设$dp[x]$表示已经抽取了$x$个球,还需要的操作次数期望。显然$dp[n]=0$。
这样就有$dp[x]=\frac{x}{n}dp[x]+\frac{n-x}{n}dp[x+1]+1$。前者表示取到了一个已经取过的球,局面不变,后者表示取到没取过的球局面改变,每次操作带来1的贡献。最终要的就是$dp[0]$
然而这里我们想要的是取到了$n$号球的次数期望值。做一些修改
$dp[x]=\frac{x}{n}dp[x]+\frac{n-x}{n}dp[x+1]+\frac{1}{n}$。有$\frac{1}{n}$的概率产生1的操作次数贡献。
推一下发现就是$dp[x]=dp[x+1]+\frac{1}{n-x}$。
那么$dp[0]=\sum_{x=1}^{n}\frac{1}{x}$。
所以点$i$的操作期望就是$\sum_{x=1}^{dep_i}\frac{1}{x}$。求一个和就行了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
int Main()
{
int n;
read(n);
std::vector<int> p(n + 1);
for (int i = 2; i <= n; ++i)
read(p[i]);
Combinatorics<modint> combinatorics(n);
std::vector<modint> sum(n + 1);
for (int i = 1; i <= n; ++i)
sum[i] = sum[i - 1] + combinatorics.inv[i];
std::vector<int> dep(n + 1);
modint ans = 0;
for (int i = 1; i <= n; ++i)
{
dep[i] = dep[p[i]] + 1;
ans += sum[dep[i]];
}
printf("%d\n", ans);
return 0;
}
|
总结:类似题目好像CF也有一道。那个题是这样的:每次找一个白点染色,把整棵子树染黑。求操作次数期望。考虑生成一个操作序列$P$,点$P_i$提供价值当且仅当$P_i$的祖先们都在$i$后面,概率为$\frac{1}{dep_i}$。
而这道题首先是有放回地取数,操作序列是无穷的。其次我们同样只需要考虑点$i$的路径,因为只有这样才对点$i$的答案造成影响。通过一个简单的期望DP推出公式。
期望DP一般都是逆推,因为终止局面的期望值是最好计算的。
ARC185D.Random Walk on Tree
有$N*M+1$个节点,下标从0开始。点$i$连接到$max(i-N,0)$。
现在从点0出发,问第一次走到所有点的期望。
$N,M \leq 200000$
把图画出来就是一个0点下面挂了$N$个长度为$M$的串。显然每一个串需要走到第$M$个数才能走完所有点。那么走完所有点等价于走完了所有串的末尾,且对于位于0点所处的局面,只有走到一个串的末尾才能改变,因此我们只关注目前访问的串末尾的数量
设$dp[i]$表示访问了$i$个不相同的末尾,目前在0点仍需要访问的串末尾数,有$dp[N]=0$。
那么有$dp[i]=\frac{N-i}{N}dp[i+1]+\frac{i}{N}dp[i]+1$。
在访问一个末尾的时候,局面是独立且相同的,考虑一段操作序列,只在最后出现访问到末尾并走回0。那么前面的所有操作,这些不影响局面的无效操作都可以看做是跟最后那段访问到末尾是同一个串上的操作——因为前面的无效操作所属的串是无关紧要的,于是访问到一个串的末尾的操作期望次数等价于在独立的一个串上走到末尾的操作期望。
这可以看做是一个简单的路径图上的随机游走问题。
设$E(X_i)$表示从$i$第一次走到$i+1$的期望次数。
那么有$E(X_i)=\frac{1}{2}+\frac{1}{2}(1+E(X_{i-1}+E(X_i))=E(X_{i-1})+2$,有$E(0)=1$。
于是第一次从0走到$M$的期望就是$\sum_{i=0}^{M-1}E(i)$,答案是$M^2$.走过去再回来相当于两次随机游走,因此是$2M^2$。
由于最后一次走到末尾就可以停,不需要回到0点,因此总答案是
$$dp[0] * 2M^2-M^2$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
int Main()
{
int n, m;
read(n, m);
Combinatorics<modint> combinatorics(n);
modint ans = 0;
for (int i = 1; i <= n; ++i)
ans += combinatorics.inv[i];
ans *= 2 * n;
ans *= 1ll * m * m;
ans -= 1ll * m * m;
printf("%d\n", ans);
return 0;
}
|
总结一下:
第一个重点在于分清楚图的样子;
第二个重点是,即便是多个串,走到任意一个串的末尾的期望步数等价于只有一个串走到末尾的期望步数。这是因为刨去最后走到末尾的步数序列,前面的操作是无效且不改变局面的,那么这段操作访问的串的编号无关紧要,因为存在$N$种长度为$L$的无效操作(只换编号那种),每种概率是$\frac{1}{N}$,乘起来是1,等价于只有一种编号。
第三个重点是随机游走问题,这也是卡了我很久的地方。这部分局面考虑的是一条边的局面,而不是点的局面,图上的随机游走问题考察的局面是边。同样这也是考虑有效操作——走一条$x->y$的路径,访问的边是$p_1,p_2,…,p_k$,只有$p_i$是有效的,其它操作不改变局面。
AGC002D.Stamp Rally
单个询问满足二分性,但是为了在二分的过程中判断答案$mid$是否合法,需要维护一个前$mid$个节点组成的并查集。而当并查集已知的时候判断单个询问是否合法是$O(1)$的。
这里如果使用可持久化并查集就可以在线回答问题。
而将询问离线,使用整体二分就可以在分治的时候维护并查集,快速对大量询问进行判定。
时间复杂度$O((n+q)log_2 n)$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
|
struct CancelableDSU
{
public:
CancelableDSU() : n(0) {}
explicit CancelableDSU(int _n) : n(_n), parent_or_size(_n + 1, -1) {}
int merge(int a, int b)
{
int x = leader(a), y = leader(b);
if (-parent_or_size[x] < -parent_or_size[y])
std::swap(x, y);
h.push_back({x, y, parent_or_size[x], parent_or_size[y]});
if (x == y)
return x;
parent_or_size[x] += parent_or_size[y];
parent_or_size[y] = x;
return x;
}
std::array<int, 4> cancel()
{
auto [x, y, sx, sy] = h.back();
h.pop_back();
parent_or_size[y] = sy;
parent_or_size[x] = sx;
return {x, y, sx, sy};
}
bool same(int a, int b)
{
return leader(a) == leader(b);
}
int leader(int a)
{
if (parent_or_size[a] < 0)
return a;
return leader(parent_or_size[a]);
}
int size(int a)
{
return -parent_or_size[leader(a)];
}
std::vector<std::vector<int>> groups()
{
std::vector<int> leader_buf(n + 1), group_size(n + 1);
for (int i = 1; i <= n; i++)
{
leader_buf[i] = leader(i);
group_size[leader_buf[i]]++;
}
std::vector<std::vector<int>> result(n);
for (int i = 1; i <= n; i++)
{
result[i].reserve(group_size[i]);
}
for (int i = 1; i <= n; i++)
{
result[leader_buf[i]].push_back(i);
}
result.erase(
std::remove_if(result.begin(), result.end(),
[&](const std::vector<int> &v)
{ return v.empty(); }),
result.end());
return result;
}
private:
int n;
// root node: -1 * component size
// otherwise: parent
std::vector<std::array<int, 4>> h;
std::vector<int> parent_or_size;
};
int Main()
{
int N, M;
read(N, M);
std::vector<std::array<int, 2>> edges(M + 1);
for (int i = 1; i <= M; ++i)
{
auto &[u, v] = edges[i];
read(u, v);
}
int Q;
read(Q);
std::vector<std::array<int, 3>> qry(Q + 1);
for (int i = 1; i <= Q; ++i)
{
auto &[x, y, z] = qry[i];
read(x, y, z);
}
std::vector<int> ans(Q + 1);
CancelableDSU dsu(N);
std::function<void(int, int, const std::vector<int> &)> solve = [&](int l, int r, const std::vector<int> &q)
{
if (l == r)
{
for (int i : q)
ans[i] = l;
auto [u, v] = edges[l];
dsu.merge(u, v);
return;
}
int mid = (l + r) >> 1;
for (int i = l; i <= mid; ++i)
{
auto [u, v] = edges[i];
dsu.merge(u, v);
}
std::vector<int> ql, qr;
for (int i : q)
{
auto [x, y, z] = qry[i];
int size = dsu.size(x);
if (!dsu.same(x, y))
size += dsu.size(y);
if (size < z)
qr.push_back(i);
else
ql.push_back(i);
}
for (int i = l; i <= mid; ++i)
dsu.cancel();
solve(l, mid, ql);
solve(mid + 1, r, qr);
};
std::vector<int> q(Q + 1);
for (int i = 1; i <= Q; ++i)
q[i] = i;
solve(1, M, q);
for (int i = 1; i <= Q; ++i)
printf("%d\n", ans[i]);
return 0;
}
|
ABC254F.Rectangle GCD
累了,做个水题。
最大公约数是支持差分的。
$gcd(a,b)=gcd(a,b-a)$
这一步也叫更相减损之术,是我们中国数学家的智慧。
我们考虑一个网格的公约数。
先看一行的情况,假设行为$i$,列为$[c1,c2]$
$gcd(a[i]+b[c1], a[i]+b[c1+1], … ,a[i]+b[c2])$
当你去做差分的时候会发现$a[i]$被减掉了。
就是
$gcd(a[i]+b[c1], b[c1+1]-b[c1], …, b[c2]-b[c2-1])$
前一个数是网格上一个点,后面就是$b$的差分数组的一个区间。
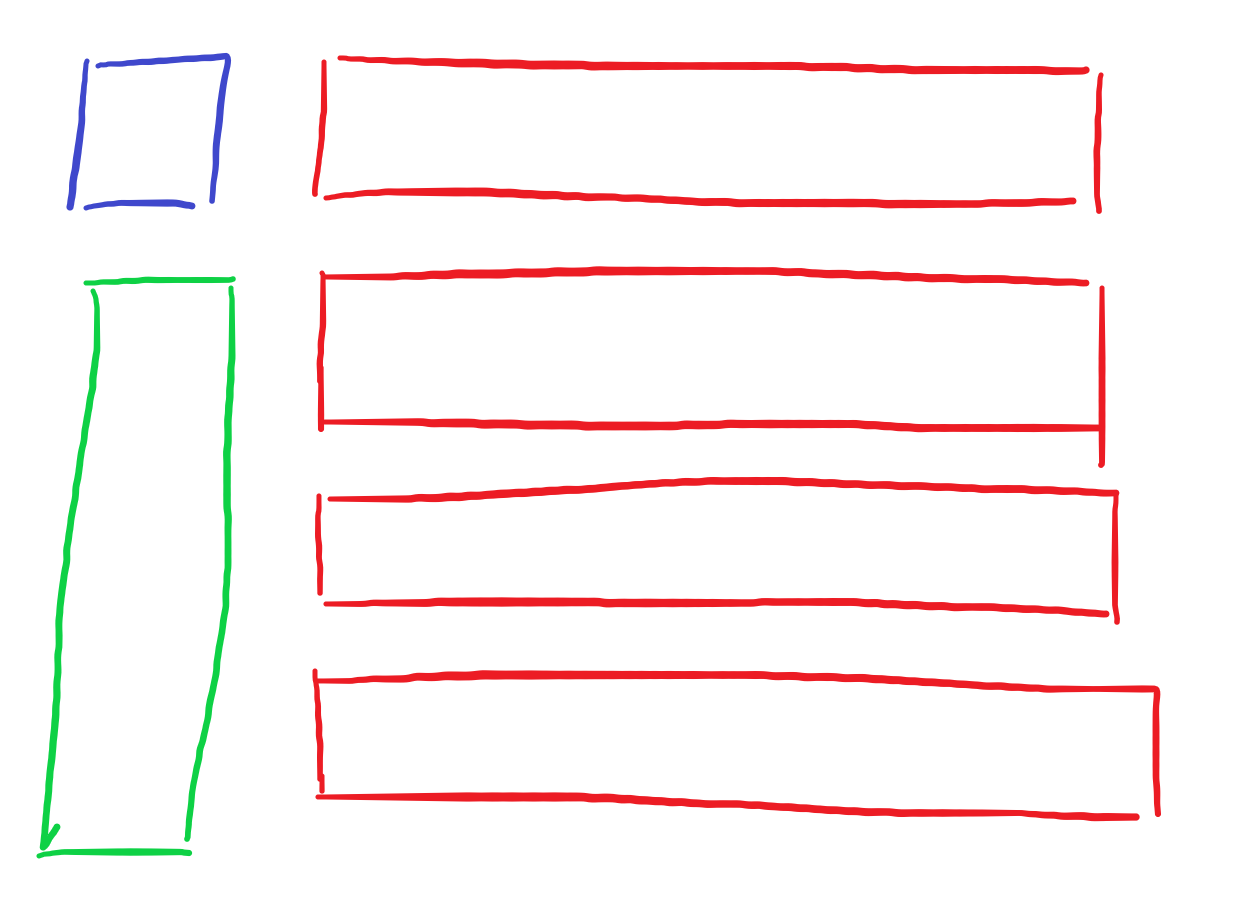
那么一次对网格的查询可以剖成红色的行(对应$b$的差分数组的区间)、绿色的列(对应$a$的差分数组的一个区间),以及蓝色的格子(左上角)。
分别用区间查询数据结构(ST表,线段树)来做区间查询。
因此一次查询操作要在$a$差分里做区间查询、$b$差分里做区间查询以及和左上角的数,用这三个数来做GCD。
ARC095C.MUL
有$N$个宝石,价值为$a[i]$,有正有负,如果砸掉了宝石$i$,那么下标为$i$的所有倍数的宝石都消失了;
求能留下的宝石价值最大。
我们反过来看,如果宝石$i$被留下,那么$i$的所有约数都得被留下,这就形成了闭合子图的概念。
因此解法即为最大权闭合子图。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
int Main()
{
int n;
read(n);
std::vector<int> a(n + 1);
for (int i = 1; i <= n; ++i)
read(a[i]);
Flow G(n + 2);
int S = 0, T = n + 1;
for (int i = 1; i <= n; ++i)
{
for (int j = 2; j * i <= n; ++j)
G.addEdge(j * i, i, Flow::INF);
}
ll ans = 0;
for (int i = 1; i <= n; ++i)
if (a[i] > 0)
G.addEdge(S, i, a[i]), ans += a[i];
else if (a[i] < 0)
G.addEdge(i, T, -a[i]);
auto cut = G.flow(S, T);
ans -= cut;
std::cout << ans << std::endl;
return 0;
}
|